
Kim Seon Deok
[컴퓨터 구조] 4-3. Pipeline Processor 본문
RISC-V Pipeline processor 구현
"computer organization and design risc-v"를 참고하여 system call을 제외한 RISC-V 32 bit 모든 유형의 ISA에 대해 구현해 보았습니다.
case1) System verilog로 구현 후 Verilator를 사용해 synthesize
https://github.com/du6293/pipeline_processor_systemverilog
GitHub - du6293/pipeline_processor_systemverilog: RISC-V pipeline processor with system verilog
RISC-V pipeline processor with system verilog. Contribute to du6293/pipeline_processor_systemverilog development by creating an account on GitHub.
github.com
case2) C언어로 구현 후 gcc환경에서 결과 확인
https://github.com/du6293/pipeline_processor_c
GitHub - du6293/pipeline_processor_c: RISC-V 5-stage pipeline cpu C
RISC-V 5-stage pipeline cpu C. Contribute to du6293/pipeline_processor_c development by creating an account on GitHub.
github.com
Pipeline Analogy
파이프라이닝은 여러 명령어가 중첩되어 실행되는 기술이다.
리소스를 중복해서 사용하는 멀티 사이클과는 다르게 파이프라이닝은 리소스를 중복시키지 않고 각 stage마다 별개의 리소스를 사용한다.


왼쪽은 멀티사이클을, 오른쪽은 파이프라이닝을 세탁과정에 비유한 그림이다.
두 과정 모두 한번의 세탁을 끝내는 데 2시간이 걸린다.
순차적인 멀티사이클은 전체적인 세탁을 끝내는 데 8시간이 걸리고, 파이프라이닝은 7.5시간이 걸린다.
파이프라이닝이 시간이 더 짧게 걸리는 이유는 모든 것이 병렬로 동작하며 같은 시간에 더 많은 일감을 처리할 수 있기 때문이다.
세탁물의 양이 줄어든다고 해서 한번의 세탁을 끝내는 데 걸리는 시간이 줄어드는 것은 아니다.
하지만 세탁물의 양이 많을 때에는 한번에 처리해야하는 양이 증가하므로 일을 끝내는 데 걸리는 전체시간이 단축된다.
하나의 작업의 단계들 중 모든 단계가 거의 같은 시간이 걸리며 할 일이 충분히 많다면 파이프라이닝에 의한 속도향상은 파이프라인의 단계 수와 같다.(=스테이지 수에 비례)
파이프라이닝한 프로세서에도 명령어 실행에서 같은 원리가 적용되어 속도를 증가시킨다.
MIPS Pipeline
MIPS명령어 실행단계는 5단계가 걸린다.
1.Instruction Fetch(IF) : 메모리에서 명령어를 instruction register가져온다.
2.Instruction Decode(ID) : 명령어를 해독함과 동시에 레지스터를 읽는다. (MIPS 명령어는 형식이 규칙적이므로 읽기와 해독이 동시에 일어날 수 있다.)
3.Execution(EX) : 연산을 수행하거나 주소를 계산한다.
4.Memory(MEM) : 데이터 메모리에 있는 피연산자에 접근한다.
5.Write back(WB) : 결과값을 레지스터에 쓴다.
Pipeline performance
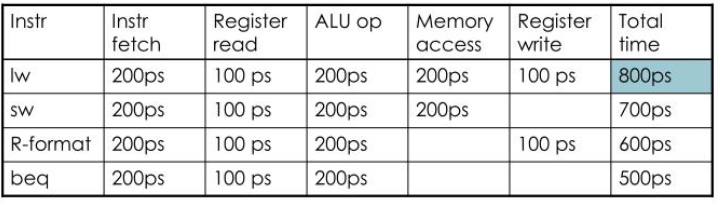
가장 느린 명령어는 800ps인 lw이다. 파이프라인 구현에서는 모든 단계가 한 클럭 사이클에 처리된다. 따라서 클럭 사이클은 가장 느린 동작을 수용할 만큼 충분히 길어야 한다. 그렇기 때문에 모든 명령어에 필요한 시간은 800ps이다.
위의 표에서 빈 공간의 시간손실이 발생하지만 대신 한번에 5개의 명령어를 수행할 수 있기 때문에 오히려 성능은 향상된다.

위 명령어 3개를 수행하는데, single cycle을 사용하면 total 2400ps가 걸리고, pipeline을 사용하면 1300ps가 걸린다.
파이프라이닝은 개별 명령어의 실행시간을 줄이지는 못하지만 대신 명령어 처리량을 증대시킴으로써 성능을 향상시킨다.
Pipeline and ISA design
MIPS명령어는 파이프라인 실행을 위한 것이다.
1.모든 MIPS명령어는 같은 길이를 갖는다.
- 이 제한 조건은 fetch단계와 decode단계를 쉽게 해준다.
- 명령어 길이가 1바이트에서부터 15바이트까지 변하는 x86명령어 집합에서는 파이프라이닝이 생각보다 힘들다.
2.MIPS는 몇 가지 안되는 명령어 형식을 가지고 있다.
- 모든 명령어에서 근원지 레지스터 필드는 같은 위치에 있다.
- 이 대칭성은 두번째 단계에서 어떤 종류의 명령어가 decode되었는지 결정하는 동안 register file read를 동시에 할 수 있다.
3.MIPS는 메모리 피연산자가 LOAD와 STORE저장 명령어에서만 나타난다.
- 메모리 주소를 계산하기 위해 실행 단계를 사용하고 다음 단계에서 메모리에 접근할 수 있다.
4.MIPS피연산자는 메모리에 align되어있어야 한다.
- 한 데이터 전송 명령어 때문에 메모리 접근을 두번 하는 경우는 없다.
- 프로세서와 메모리 사이의 데이터 전송은 항상 파이프라인 단계 하나 에서 처리된다.
MIPS Pipelined Datapath
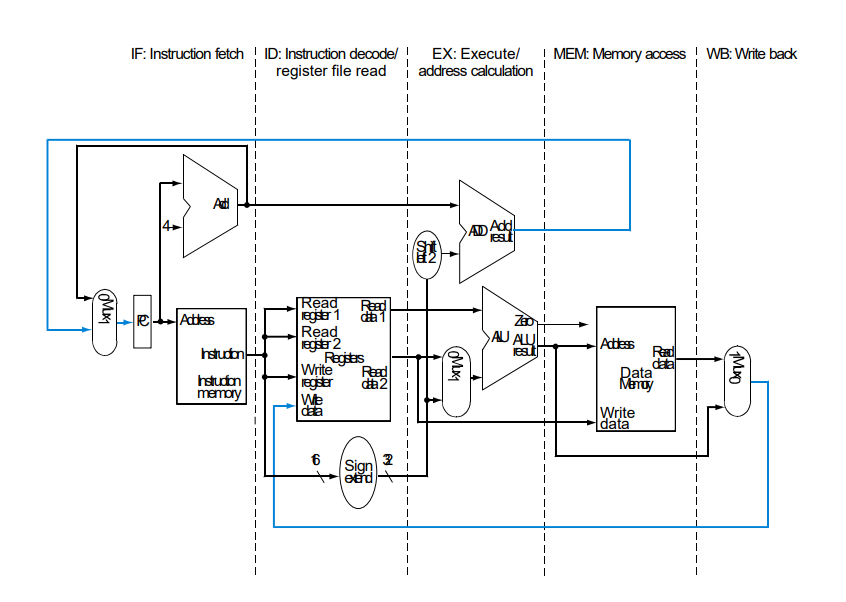
MIPS명령어에는 5단계로 나누면 다음과 같다.
각 stage가 나뉘었고 한 stage를 거칠때마다 플립플롭이 추가된다.
한 플립플롭에서 다음 플립플롭까지가 한 stage이고 1클럭동안 한 stage가 수행된다.
1. Instruction Fetch(1번째 클럭)
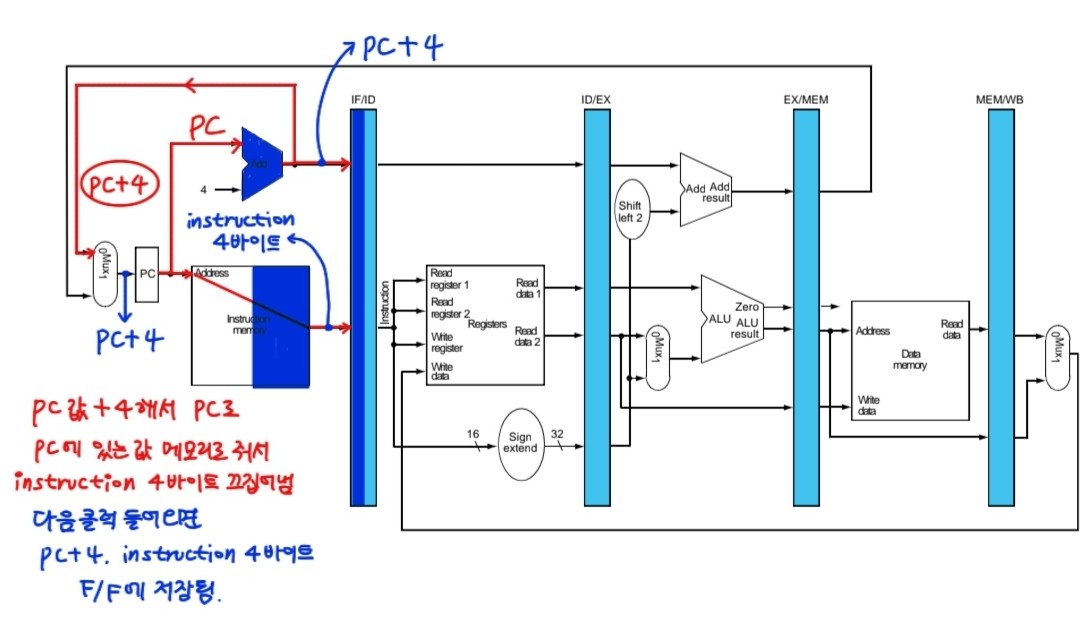
1. instruction memory로 전달해서 instruction 명령어 4바이트를 끄집어냄
2.다음클럭 들어오면 PC + 4, instruction 4바이트값을 플립플롭에 저장해둔다.
3. adder를 통해 PC + 4 를 하고 다시 PC에 저장되어 다음 클럭이 들어오면 증가한 값이 사용된다.
2. Instruction decode, R-Fetch(2번째 클럭)

1.플립플롭에 저장되어 있던 값 reg1, reg2로 주고 두 레지스터의 값 다음 플립플롭에 저장
2.immediate값(LOAD, STORE), PC + 4 값 다음 플립플롭에 저장
3. Execute for load(3번째 클럭)
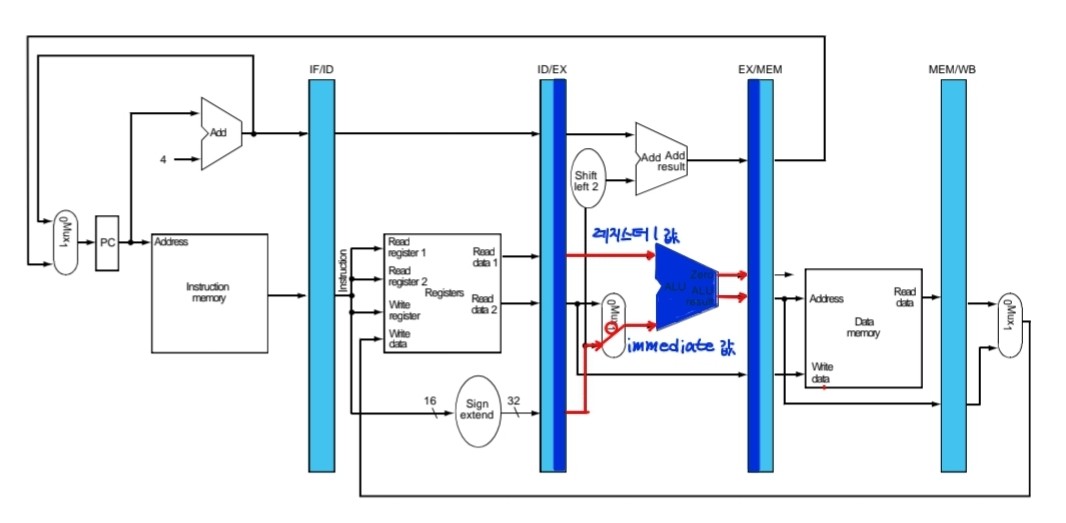
1.플립플롭에 저장되어 있던 reg1값과 immediate값 ALU연산. 이때 결과값은 메모리에서 읽을 주소이고 이를 다음 플립플롭에 저장. destination register값 다음 플립플롭에 저장
4.Memory for load(4번째 클럭)
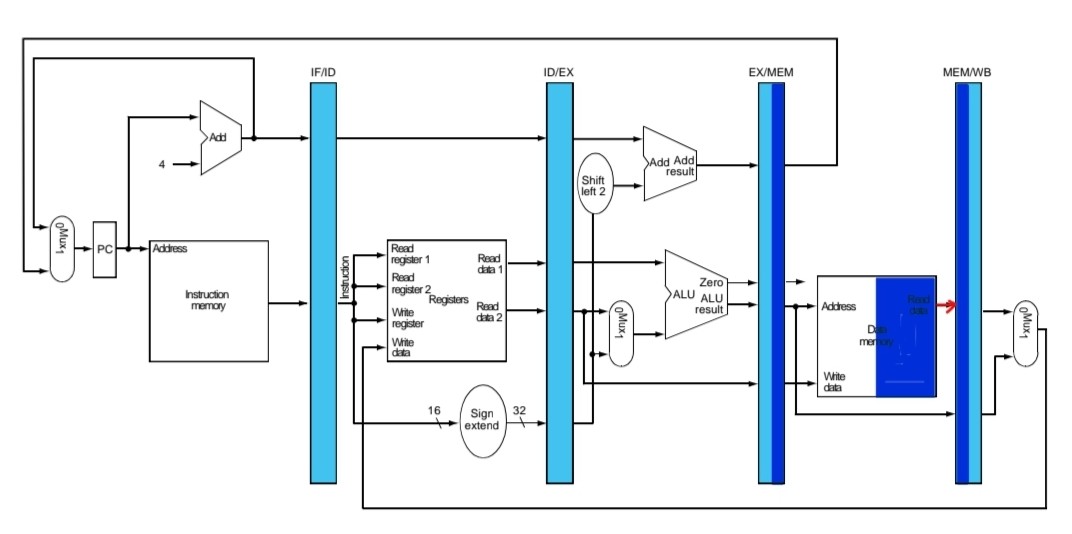
1.플립플롭에 저장되어 있던 주소값 data memory에 전달하고 read한 데이터, destination register값 다음 플립플롭에 저장.
5.Write Back for load(5번째 클럭)
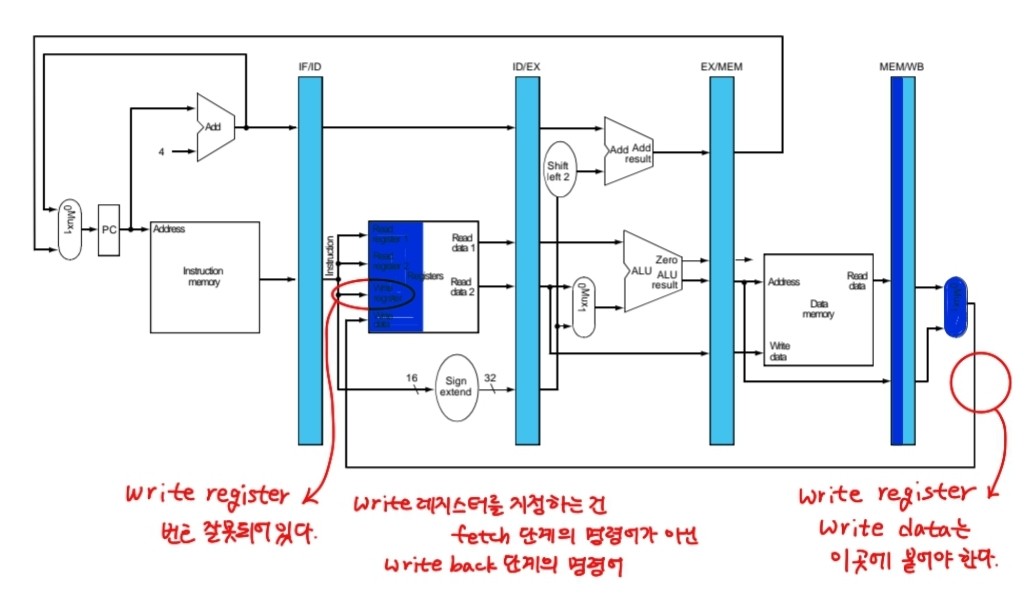
1.플립플롭에 저장되어있던 destination data, read한 데이터 mux0번 통과하고 레지스터로 돌아가 write한 후 저장
하지만 오류가 있다. write register, write data를 결정하는 건 fetch단계의 명령어가 아닌 write back단계의 명령어기 때문에 이를 수정해줄 필요가 있다.
Corrected Datapath
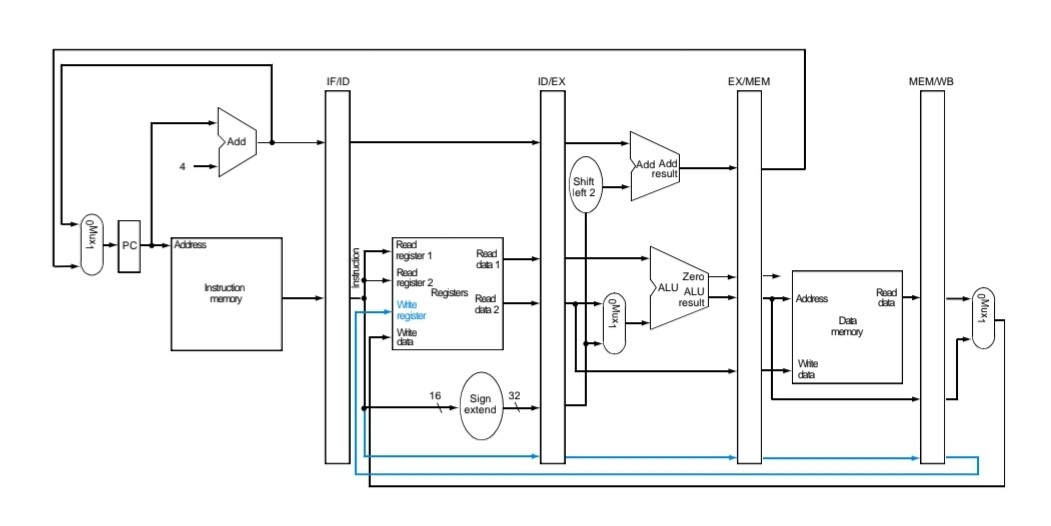
fetch단계의 플립플롭에서 write register로 가능 경로가 사라지고 write back단계의 플립플롭에서 write register로 가는 destination경로를 추가해 datapath를 수정
3.Execute for Store(3번째 클럭)
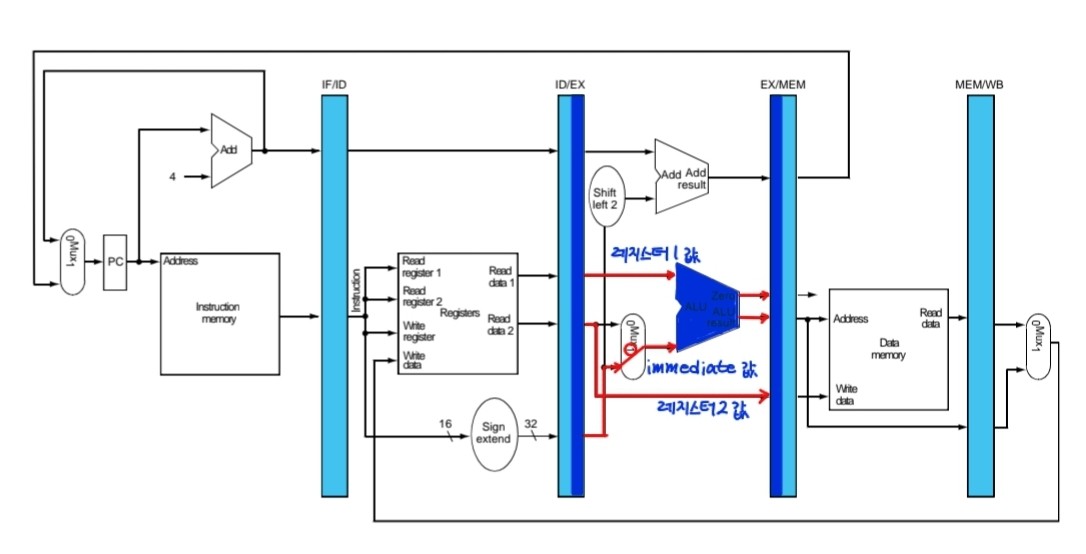
1. 플립플롭에 저장되어있던 reg1값과 immediate값 ALU에서 연산하고 이 때 결과값은 메모리에서 읽을 주소이다. 이를 다음 플립플롭에 저장한다.
2. reg2값 다음 플립플롭에 저장
3. 맨 아래 mux에 따라 결정된 destination 레지스터 값 다음 플립플롭에 저장
4.Memory for Store(4번째 클럭)
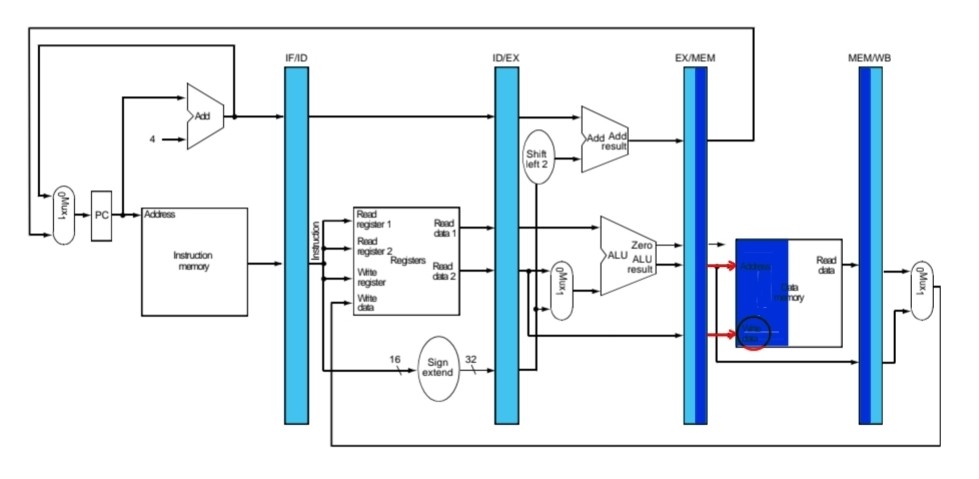
1. 플립플롭에 저장되어 있던 주소값 data memory로 전달.
2. 플립플롭에 저장되어있던 reg2값 data memory에 write
3. destination 레지스터 값 다음 플립플롭에 저장
5.Write back for Store
4단계에서 Store작업은 모두 끝났기 때문에 아무것도 하지 않는다.
Multiple cycle pipeline diagram
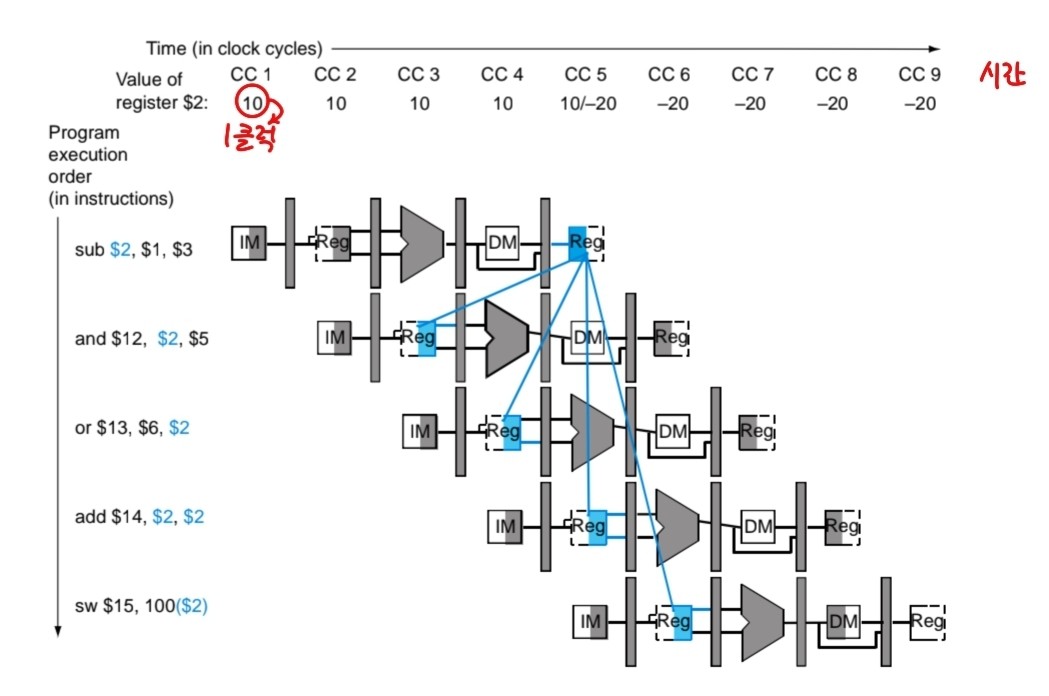
5개의 단계가 파이프라인형태로 진행되는 모습이다.
첫번째 명령어가 instruction fetch될 때 나머지는 아무것도 하지 않는다.
첫번째 명령어는 decode & R- Fetch될 때 두번째 명령어 instruction fetch
첫번째 명령어가 execute될 때 두번째명령어 decode & R-Fetch, 세번째 명령어 instruction fetch
....
5개의 명령이 쭉 지속되면서 성능은 5배가 된다.
파이프라인을 사용하면 클럭을 잘게 쪼개 클럭속도가 높아지고 한 단계에 해당하는 클럭주기가 짧아지며 한 단계마다 할 일이 줄어든다.
이전 pentium4가 성능의 정점을 찍었을 때가 바로 intel이 파이프라인 스테이지를 가장 잘게 쪼갰던 시기이다.
하지만 그에 따라 에너지 소모도 컸었다. (trade off관계)
이전에 성능을 향상시키기 위한 방법에서 에너지 소모를 줄이려면 클럭을 낮춰야 한다는 것처럼, 스테이지를 잘게 쪼개는 것만이 절대적인 해결책은 아니지만 파이프라인을 잘게 쪼갤수록 그에 비례해 동시에 처리할 instruction 수가 증가한다.
따라서 암다르 법칙을 활용해 최적의 성능을 뽑아내는 것이 중요하다.
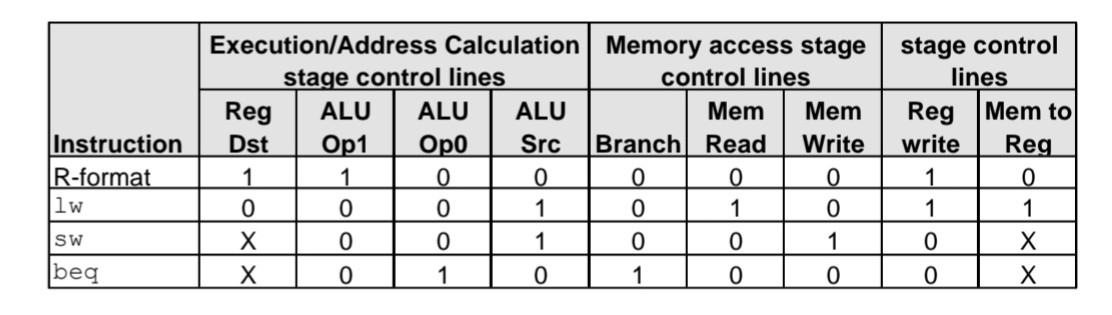
Simplified Pipeline control

ALU control 아랫부분에 mux가 추가되었다.
R type 명령어는 op6비트, rs5비트, rt5비트, rd5비트로 구성된다. 이 중 rd5비트를 사용한다.
Load 명령어는 op6비트, rs5비트, rt5비트,immediate16비트로 구성된다. 이 중 rt5비트를 사용한다.
사용하는 명령어의 위치 필드(destination register)가 명령어가 R type인지 Load명령어인지에 따라 달라지기 때문에 mux를 통해 선택적으로 컨트롤하도록 만든 것이다. (R- type이면 mux1, Load면 mux0)
Pipeline control
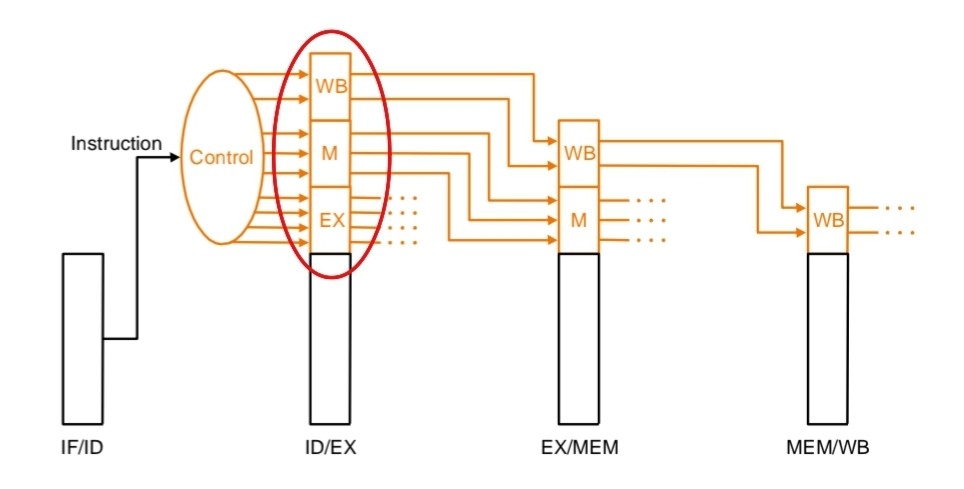
single cycle : 1클럭 동안 1명령어 수행하기 때문에 조합회로로 control unit 생성
multiple cycle : 여러 클럭 동안 1 명령어 수행하기 때문에 명령어를 입력으로 하는 state machine 을 돌림
pipeline : 현재명령어와 다음 명령어가 관련이 없다. 하나의 명령어를 여러 단계를 거치도록 함. 각 단계별로 한 칸씩 밀리면서 다음 명령을 실행하게 함으로써 병렬적으로 수행하는 효과를 얻음. 동시에 수행하는 명령어의 수는 파이프 라인의 단계를 몇개로 쪼갰는지, 스테이지 수에 비례한다. 한 단계의 명령이 지배하는 영역은 한 플립플롭에서 다음 플립플롭까지이다. 한 단계를 1클럭동안 수행하기 때문에 입력을 명령어로 해서 그 명령에 따라 현재단계의 제어 word를 생성하는 조합회로로 control unit을 만들 수 있다.
fetch, decode는 명령어에 상관없이 발생하므로 표시x
excute, write back은 명령어에 따라 달라지므로 control unit을 통해 제어
'컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] 4-5. Exception & Dynamic multiple issue (0) | 2022.11.15 |
|---|---|
| [컴퓨터 구조] 4-4. Hazard (0) | 2022.11.14 |
| [컴퓨터 구조] 4-2. Multiple - Cycle Processor (0) | 2022.11.12 |
| [컴퓨터 구조] 4-1. Single - Cycle Processor (0) | 2022.11.12 |
| [컴퓨터 구조] 2-2. MIPS (0) | 2022.11.11 |



