
Kim Seon Deok
[컴퓨터 구조] 4-5. Exception & Dynamic multiple issue 본문
Data Hazards for Branches
- R-type명령어 2개 온 다음 beq명령어가 오는 경우

forwarding으로 decode stage에 add단계에서 나온 레지스터 값을 집어넣을 수 있다.
- Load 명령어 다음 R-type 명령어그다음 beq명령어가 오는 경우

Load 명령어가 온 다음 R-type명령어가 왔기 때문에 data hazard가 발생한다. 이 때 add명령어는 $1을 사용하지 않으므로 stall을 할 필요는 없다.
Load 명령어의 $1을 그다음에 오는 beq명령어에서 사용하기 때문에 branch hazard가 발생하므로 한 클럭 stall을 해주어야 한다.
- Load 명령어 다음 beq명령어가 오는 경우

Load명령어에서 memory단계 이후 생성되는 wirte back할 값이 beq명령어의 decode 단계에서 사용되어야 하므로 2 클럭 stall을 해주지 않으면 문제가 발생한다.
Bit predictor : shortcoming
- 1비트 분기예측방법 : 거의 매번 분기하다 어쩌다 한번 분기하지 않을 때 한번이 아닌 두번의 잘못된 예측을 할 수 있다. → 바로 이전의 상태에 따라 결정
ex) 열 번 중 9번을 연속해서 분기하고 마지막에는 분기하지 않는 순환문 분기
첫번째와 마지막 순환문 반복에서 예측을 잘못할 것이다. 마지막 반복에서는 이 시점까지 연속해서 아홉 번 분기가 일어났기 때문에 잘못된 예측을 피할 수 없다.
이 같은 약점을 보완하기 위해 예측비트를 더 많이 사용할 수 있다.
- 2비트 분기예측방법 : 예측이 두 번 연속으로 잘못되었을 때 예측값이 바뀐다. → 바로 이전 두번의 상태에 따라 결정
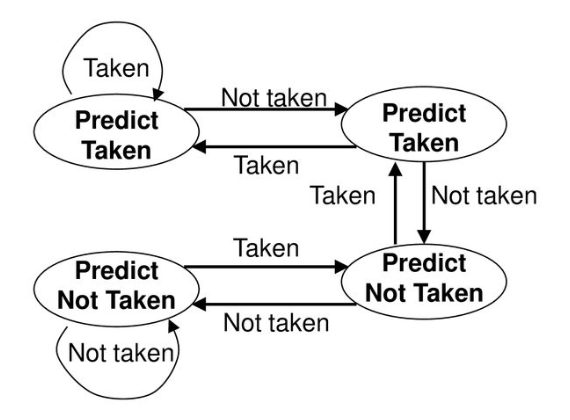
두 번 연속 taken → taken
두 번 연속 not taken → not taken
1비트 대신 2비트를 사용하면 예측이 틀리는 경우를 한번으로 줄일 수 있다.
2비트 방법은 카운터 기반 예측기의 일반적인 예인데, 예측이 맞으면 증가하고 틀리면 감소한다.
이 카운터는 카운팅 범위의 중간값을 분기하는 경우와 분기하지 않는 경우의 경계로 삼는다.
Calculating the branch target
branch target에 해댱하는 것을 미리 계산해 branch target buffer에 저장하고, prediction이 correct한 경우 한 클럭의 stall도 일어나지 않도록 만드는 것이다.
Delay slot
branch 발생 후 어디로 분기할 지 미리 판단하기 어려워 그로인한 stall이 발생되기 때문에 문제가 생겼었다.
그렇기 때문에 branch 다음에 해당되는 instruction을 취소해야는 경우를 아예 만들지 않으면 어떨까 하고 branch 다음에 해당되는 instruction을 무조건 수행해야 하는 명령어라 가정하면 다음과 같다.
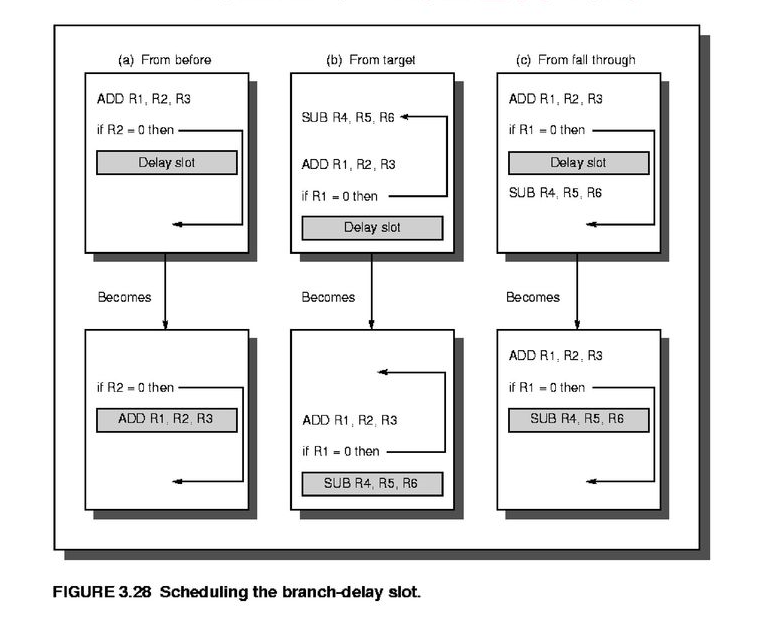
delayed branch : stall을 줄이고자 하는 하나의 방법
beq문이 맞았건 틀렸건 간에 그 다음 instruction 무조건 수행하도록 한다.
jump와 상관없이 beq 다음 명령어가 취소되지 않게 하여 stall발생을 막는 방법이다.
(a) : 앞에 있는 명령어를 가져옴
(b) : target에서 가져옴
(c) : 그 다음것을 가져옴
Exceptions and Interrupts
예외나 인터럽트는 분기나 점프가 아니면서 명령어 실행의 정상적인 흐름을 바꾸는 사건이다.
ex) blue screen, div 0, power failure...
control unit을 설계할 때 예외를 신중하기 다루지 않으면 정확한 설계가 어려워지고 성능이 떨어질 수 있다.
Exception : 프로그램 실행을 방해하는 계획되지 않은 사건. 오버플로 검출에 사용된다. (CPU내부에서 발생)
Interrupt : 프로세서 외부로부터 오는 예외(외부 입출력 장치에서 발생)
Pipeline with Exceptions
exception까지 처리할 수 있는 내부구조이다.

프로그램이 진행되다가 갑자기 다른 프로그램을 진행하게 되는데, 이 때 새로운 프로그램이 발생했을 때 PC값을 바꾸어주어야 한다.
- exception 처리를 위한 번지로 뛸 수 있는 경로 추가
- 왜 에러가 났는지 , 몇 번지에서 에러가 났는지에 해당하는 error 원인과 그 때의 PC값을 저장하는 메모리도 추가되었다. (예외가 발생하면 메모리 상태, 레지스터 상태 전부 하드디스크에 기록해야 한다.)
- Exception flush : 프로그램을 멈춰야 하는 경우 ALU에서 정지시킨다. 모든 control unit을 0으로 만들어 뒤에 남은 다른 명령어를 전부 flush함.
- ex)

add까지 수행 후 exception 발생하는 상황이다. add 명령어의 pc값을 저장하고
이후 50 54 명령어는 flush하고 exception처리를 위해 80000180부터 프로그램을 수행해야 한다.
speculation
컴파일러나 프로세서가 어떤 명령어의 결과를 예측하여 다른 명령어들과의 종속성을 제거하도록 하는 기법이다.
에측을 기반으로 컴파일러나 프로세서가 명령어의 특성에 대해 추측할 수 있게 해, 이 명령어에 종속적일 수 있는 다른 명령어들의 실행을 시작할 수 있게 한다.
speculation의 어려운 점
추정이 잘못될 수 있다는 것이다. 따라서 speculation이 올바른 지 확인할 방법과 speculation에서 실행했던 명령어들을 되돌리거나 그 효과를 취소하는 방법을 포함해야 한다.
correct : write back
incorrect : roll - back
Instruction Level Parallelism(ILP)
파이프라이닝은 프로그램의 빠른 수행을 목적으로 하기 때문에 명령어들 사이의 병령성을 이용한다.
ILP 은 명령어 사이의 병렬성을 말한다.
<ILP를 증가시키는 방법>
1. 파이프라인의 깊이를 증가시켜 더 많은 명령어를 중첩시킴 = 파이프라인을 잘게 쪼갬
클럭사이클이 줄어들어 1 stage별로 할 수 있는 일 단순화된다.
하지만 복잡도가 증가해 hazard, forwarding 증가하여 stall이 증가하게 된다.
그리고 signal이 빠르게 왔다갔다 하므로 power consumption이 증가하게 되어 성능이 떨어지게 된다.
2. multiple issue : 컴퓨터 내부의 구성요소들을 여러 벌 갖도록 해 매 파이프라인 단계에서 다수의 명령어를 내보낼 수 있도록 함 = 프로그램 instruction을 1줄씩 fetch해 수행하는 것이 아니라 두 줄씩 fetch해 수행
끌어온 두 instruction 간 data hazard 발생하면 수행이 되지 않는다. 또한 동시에 수행해야 하므로 ALU 개수도 2배가 되는 등 모든 유닛이 2배가 되어 dependency가 발생한다.
컴파일러가 할 일과 하드웨어가 할 일을 나누는 방법에 따라 static, dynamic으로 나뉜다.
- static multiple issue : 많은 결정들이 실행 전에 컴파일러에 의해 이루어지는 multiple issue

2개의 명령어 한꺼번에 수행되는 과정이다. 명령어 1개장 5stage이므로 명령어 2개씩 파이프라인으로 한꺼번에 수행하게되면 총 10개의 명령어를 동시에 수행할 수 있게된다. 이를 superscalar라 한다.
또한 그림에서 ALU/Branch와 Load/Store가 한 묶음으로 일어나는 데, Load/Store끼리, ALU/Branch끼리 수행되지 않는 이유는 mem단계에서 충돌이 일어나기 때문이다. 따라서 Load/Store와 ALU/Branch가 반반으로 구성되어 배치되도록 짜야 하는데 이 과정이 어렵다.
static multiple issue의 한계를 느끼고 새로운 개선책을 찾다가 만들어 낸 것이 dynamic multiple issue이다.
- dynamic multiple issue : 많은 결정들이 실행 중에 프로세서에 의해 이루어지는 multiple issue

static 단계에서는 코드를 짠 순서대로 프로그램이 수행되었다. 그러다 보니 forwarding과 stall이 발생했고, 개선하다 보니 성능의 한계에 이르렀다. 따라서 한 instruction을 여러 단계로 나누고 그 여러 단계를 각자수행하고 다시 합치는 dynamic방식을 사용하게 되었다.
dynamic scheduling pipeline은 크게 3가지 유닛으로 구성된다.
- Instruction fetch and decode unit : 명령어를 가져오고 decode하고 각각의 명령어를 실행단계의 해당 functional unit에 순서대로 내보냄 (in-order issue)
- reservation station : 연산자와 피연산자를 갖고 있는 기능 유닛 내의 버퍼
- Fuctional unit : 연산하고 결과를 내보냄. 이 때 명령어 fetch 순서와 다르게 실행(out-of-order execute)
연산이 끝나고 나면 결과값은 commit unit과 reservation station에 보내진다.
- Commit unit : 결과값을 버퍼링하고 있다 프로그램 fetch 순서대로 결과값을 정렬해 레지스터나 메모리에 결과를 write한다.(in order commit)
하지만 이후에도 Functional unit이 늘어나 commit unit에서 병목현상이 발생해 single core의 한계를 느끼고 multicore를 사용하는방식으로 변화함
pipeling 과 dynamic multiple issue는 모두 instruction 처리량을 증가시키고 ILP를 활용하려는 기술이다.
하지만 dependency가 해결될 때까지 프로세서가 기다려야 하는 경우가 많기 때문에 ILP를 활용하기 위한 소프트웨어 중심의 접근방법은 컴파일러의 능력에 의존해 dependency를 찾아내고 그 영향을 줄이는 반면, 하드웨어 중심의 접근 방법은 pipeline과 multiple issue매커니즘의 확장에 의존한다.
speculation을 하면 예측을 통해 이용할 수 있는 ILP의 양을 증가시킬 수 있지만 틀린 speculation은 성능을 저하시킬 수 있다.
컴퓨터 시스템의 성능을 향상시키기 위해 클럭의 길이를 줄이고 한 insruction이 필요로 하는 클럭의 개수를 줄여 성능을 높였다. 또한 파이프라인을 사용했다. 하지만 실제 프로그램을 짜고 명령어를 수행하다 보니 앞 명령어와 뒷 명령어 사이 dependency가 발생했다. 그로인해 3가지의 hazard가 발생했다. 하지만 더이상 클럭을 높이고 파이프라인을 잘게 나누는 방식으를 사용하기에는 한계에 이르렀다. → 멀티코어의 방식을 따르기 시작
하지만 현재 하나의 프로세서에 대해서만 프로그램을 짜는 방식을 사용하고 있고, 운영체제 또한 싱글프로세서에 맞추어져 있어 멀티프로세서에도 한계가 있다.
'컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] 5-2. Associative Caches (0) | 2022.11.17 |
|---|---|
| [컴퓨터 구조] 5-1. Direct mapped Cache (0) | 2022.11.16 |
| [컴퓨터 구조] 4-4. Hazard (0) | 2022.11.14 |
| [컴퓨터 구조] 4-3. Pipeline Processor (0) | 2022.11.13 |
| [컴퓨터 구조] 4-2. Multiple - Cycle Processor (0) | 2022.11.12 |



