
Kim Seon Deok
[컴퓨터 구조] 4-4. Hazard 본문
Hazard
hazard란 다음 명령어가 다음 클럭 사이클에 실행될 수 없는 상황을 말한다. 해저드에는 세 가지 종류가 있다.
- Structure hazards
- 주어진 클럭 사이클에 실행되도록 되어있는 명령어 조합을 하드웨어가 지원하지 못해서 계획된 명령어가 적절한 클럭 사이클에 실행될 수 없는 사건이다. >> 한 사람이 2가지 일을 동시에 할 수 있는가
- 같은 클럭 사이클에 실행하기를 원하는 명령어의 조합을 하드웨어가 지원할 수 없기 때문에 발생한다.
solution : resource duplication, cache
- Data hazards
- 명령어를 실행하는 데 필요한 데이터가 아직 준비되지 않아서 계획된 명령어가 적절한 클럭 사이클에 실행될 수 없는 사건이다.
- 어떤 단계가 다른 단계가 끝나기를 기다려야 하기 때문에 파이프라인이 지연되어야 하는 경우 발생한다.
- wirte back stage에 있는 명령어의 값을 다음 명령어의 decode & R-Fetch 단계에 사용해야 하기 때문에 발생하는 해저드
solution : forwarding, stall
- Control hazards
- fetch한 명령어가 필요한 명령어가 아니기 때문에 적절한 명령어가 적절한 클럭 사이클에 실행될 수 없는 사건이다.
- 명령어 주소의 흐름이 파이프라인이 기대한 것과 다르기 때문에 발생한다.
- 다른 명령어들이 실행되는 동안 어떤 명령어의 결과에 기반을 둔 결정을 할 필요가 있을 때 일어난다.
solution : stall, prediction
structure hazard

single cycle의 경우 instruction 메모리와 data memory가 분리되어 있다.
multiple cycle의 경우 instructino 메모리와 data memory가 하나로 합쳐져 있다.
pipeline의 경우 instruction 메모리와 data memory가 분리되어 있다.
예를 들어 load명령어의 경우, ALU연산을 통해 나온 주소값은 fetch에서 명령어를 읽을 주소를 주고 instruction 4바이트를 출력해야 한다. 그림상에서는 분리된 것 처럼 보이지만 사실 같은 하나의 메모리이다. 이렇게 되면 structure hazard가 발생하게 된다.
load에서 메모리를 액세스 해야하기 때문에 그 순간에 fetch단계에 와 있는 명령이 메모리를 액세스 하지 못한다.
solution : resource duplication
해결 1 : cache 메모리
프로세스가 액세스 하는 메인메모리에 있는 것을 좀 더 빨리 액세스 하기 위한 것
메인메모리는 하나지만 명령용 캐시(=instruction memory), 데이터용 캐시(=data memory)를 분리시킨다.
해결 2 : multiple cycle에서 1개였던 ALU를 3개로 다시 늘림.
Data hazard

sub $5, $2, $3 ; //이전에 연산한 결과가 오기 전에
and $12, $4, $5 ; // 연산한 결과값을 끌어서 쓰려 하는 경우Data hazard는 이전에 연산한 결과가 오기 전에 연산한 결과값을 끌어서 쓰려 하는 경우에 발생한다.
위와 같은 예에서, sub은 다섯번째 wb단계가 오기 전까지 결과값을 write하지 않을 것인데, 다음 명령어인 and는 그렇다면 결과값이 write될때까지 기다려야 하므로 세 클럭을 낭비하게 된다.
해결 1 : pipeline freezing
이전 명령어의 결과값이 올 때까지 다음 명령어를 수행하지 않고 기다리게 함. → 기다리는 만큼 프로그램이 진행되지 않으므로 성능 손실이 발생하게 된다.
해결 2 : forwarding :별도의 하드웨어를 추가해 정상적으로 얻을 수 없는 값을 내부 자원으로부터 일찍 받아오는 것
프로그래머가 볼 수 있는 레지스터나 메모리에 데이터가 도착할 때 까지 기다리지 않고 내부 버퍼에서 가져옴으로써 r5값을 미리 전달해 당겨와서 쓰도록 함. → 파이프라인을 freezing하지 않아도 되므로 성능 손실이 덜하다.
Forwarding path

조합회로인 Forwarding Unit을 추가하고 Forwarding unit에서는 레지스터에서 읽어온 값과 execute값, mem값을 가져와서 XOR연산을 통해 비교한다. 그 결과로 연결된 MUX 2개의 경로를 컨트롤한다.
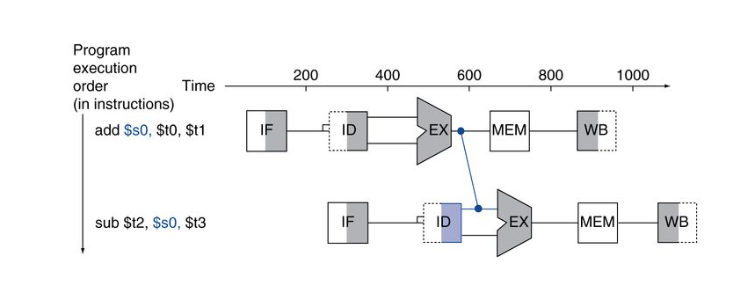
R-type명령어 이후 R-type 명령어가 왔을 땐 forwarding을 통해 해결한다.
add단계의 excute 출력을 sub의 execute단계입력으로 forwarding

Load 명령어 이후 R-type명령어가 왔을 땐 stall을 통해 해결한다.
Load 명령어의 경우 데이터 mem단계 이후의 플립플롭에 저장된 값을 write back해야 하므로 load 명령어 이후 R-type 명령어가 들어온다면 execute 단계를 저장한 플립플롭에서는 값을 전달해 줄 수 없다. 따라서 Load 명령어 이후 R-type명령어가 왔을 땐 forwarding을 하더라도 한 단계 지연이 더 필요하다.

위 그림에서 첫번째 load명령어의 결과값을 $2에 저장한다. 그리고 다다음 add명령어에서 $4를 읽어와야 하는데,
load명령어가 writeback할 시점에 add명령어는 decode & r-fetch 단계이므로 이 때는 컴파일러가 한 클럭을 반으로 나누어 왼쪽 절반은 write를 오른쪽 절반은 read를 하도록 하여 한 클럭 내에서 두 작업이 동시에 일어나지 않고 차례로 일어나도록 만들어 선후관계 문제를 해결할 수 있다. → 컴파일러의 중요성
Stall

어떤 파이프라인이 진행된다는 건 파이프라인 명령단계별로 control을 채워넣고 데이터를 전달해 진행하는 것이다.
그런데 만약 stall이 발생한다면 중간에 빈 공간이 생기게 된다. 그렇기 때문에 stall이 발생하면 control 빈공간에 제어워드를 전부 0으로 채워넣는다.
※ stall의 생성조건※
1.execute stage에 가 있는 명령어가 load
2.execute stage에 가 있는 명령어의 write back해야 하는 레지스터 번호가 내가 읽는 레지스터 번호와 일치
※Pipeline freezing 하는 방법※
1. 플립플롭 input enable을 끔 : Hazard detection unit에서 매클럭마다 i-fetch 플립플롭으로 들어오는 input을 무시
2. PC정지 : 매 클럭마다 pc값은 pc + 4 가 되어야 하는데 input enable을 꺼서 pc + 4 로 갱신되지 않게 함. → 이전단계는 클럭에 따라 진행되고 이후 단계는 멈춰있기 때문에 빈공간 생김
3. Hazard detection unit 아래 MUX를 추가하고 옆 control unit 모두 0으로 채움
Stalls and Performance
파이프라인이 완벽하게 진행된다면 매 클럭마다 하나씩 명령어가 종료되기 때문에 CPI는 1에 수렴한다.
pipeline의 stage를 잘게 쪼갠다면 1클럭 사이클타임이 감소하고 성능은 올라간다.
하지만 stall이 발생하게 되면 해당 클럭에는 종결하는 명령어가 없기 때문에 발생하는 stall만큼 성능이 저하된다.
따라서 load 다음의 명령이 해당 레지스터 번호를 액세스하지 않게 만들면 stall이 발생하지 않는다.(code scheduling)
**compiler scheduling**
lw $t1 0($t0) lw $t1 0($t0)
lw $t2 4($t0) lw $t2 4($t0)
add $t3 $t1 $t2 lw $t4 8($t0)
sw $t3 12($t0) → add $t3 $t1 $t2
lw $t4 8($t0) sw $t3 12($t0)
add $t5 $t3 $t4 add $t5 $t1 $t4
sw $t5 16($t0) sw $t5 16($t0)왼쪽은 stall이 2번 발생해 13클럭이 소요되고 오른쪽은 stall발생하지않도록 code scheduling을 진행해 11클럭이 소요된다.
Control hazards = Branch hazards

Branch가 생겨서 어떤 명령어로 jump를 해야하는 상황일 때 그 jump를 할지 말지는 ALU의 뺄셈연산(mem파이프라인단계)을 통해 결정된다. Beq명령을 만나고 jump가 일어날 때와 일어나지 않을 때의 레지스터의 위치는 달라진다.
따라서 fetch할 명령어가 늦게 결정되어 발생하는 해저드이다.
stall on branch
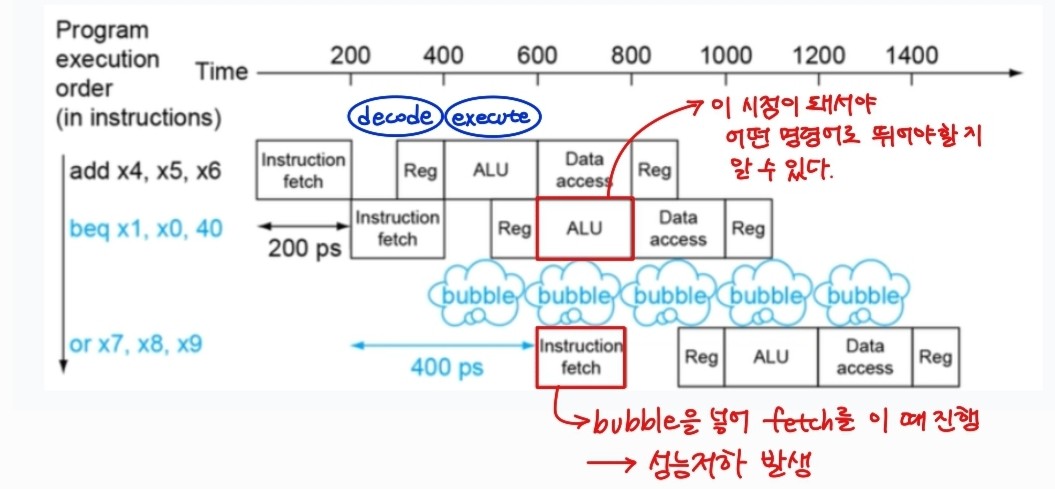
control hazard를 막기 위해 stall을 발생시키게 되면 jump발생과 상관없이 1클럭의 지연이 발생한다.
따라서 1클럭의 손실을 막기 위해 prediction을 진행한다.
Prediction
1. 분기가 일어나지 않는다고 가정

예측이 틀렸을 경우 파이프라인을 flushing
2.dynamic branch prediction : 현재 beq명령에서 분기할 지 안할 지는 이전 beq명령의 결과를 바탕으로 결정
이 때 branch prediction buffer를 사용해 지난 번 실행 시에 분기가 일어났는지 안 일어났는지의 분기여부를 나타내는 하나 이상의 비트를 갖고 있다.
Reducing branch delay

decode & R -fetch단계에서 두 레지스터값이 같은지 다른지 미리 단순한 (XOR & OR) 조합회로를 추가해주어 ALU에서 연산하지 않고도 분기가 일어날 것을 미리 판단함 → stall은 줄어들지만 별도의 forwarding unit과 mux를 추가해주어야 하므로 구현이 복잡해진다. (Forwarding unit에서는 레지스터에서 읽어온 값과 execute값, mem값을 가져와서 XOR연산을 통해 비교하는 경로도 만들어주어야함)
비교한 두 값이 같다면 PC + 4 와 immediate값을 signExtend & shift left2한 값 더해 PC값을 갱신한다.
prediction : 분기가 일어나지 않을 것이라 가정
correct : pc + 4으로 갱신
incorrect : pc + 4 + imm16으로 갱신 & 이전에 들어온 명령 무효화하고 분기한 곳의 명령 수행
출처 : https://blog.naver.com/tlsrka649/221992274008
https://slideplayer.com/slide/17938421/
'컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] 5-1. Direct mapped Cache (0) | 2022.11.16 |
|---|---|
| [컴퓨터 구조] 4-5. Exception & Dynamic multiple issue (0) | 2022.11.15 |
| [컴퓨터 구조] 4-3. Pipeline Processor (0) | 2022.11.13 |
| [컴퓨터 구조] 4-2. Multiple - Cycle Processor (0) | 2022.11.12 |
| [컴퓨터 구조] 4-1. Single - Cycle Processor (0) | 2022.11.12 |



