
Kim Seon Deok
[컴퓨터 구조] 4-2. Multiple - Cycle Processor 본문
single cycle의 critical path(Load명령어 가장 오래 걸림)로 인한 지연을 막기 위해 여러 클럭에 걸쳐 하나의 명령어를 수행하는 multiple cycle 방법으로 변화했다.
한 instruction을 여러 클럭에 나눠서 수행할 수 있도록 함으로써 명령어마다 필요로 하는 클럭의 개수를 다르게 할 수 있게 되었다.
single cycle : 1clock & control unit 1개 >> control unit 조합회로로 구현
multiple cycle : 클럭마다 control 달라짐 >> 명령어를 입력으로 하여 state machine으로 control unit 구현 & 리소스 중복 가능
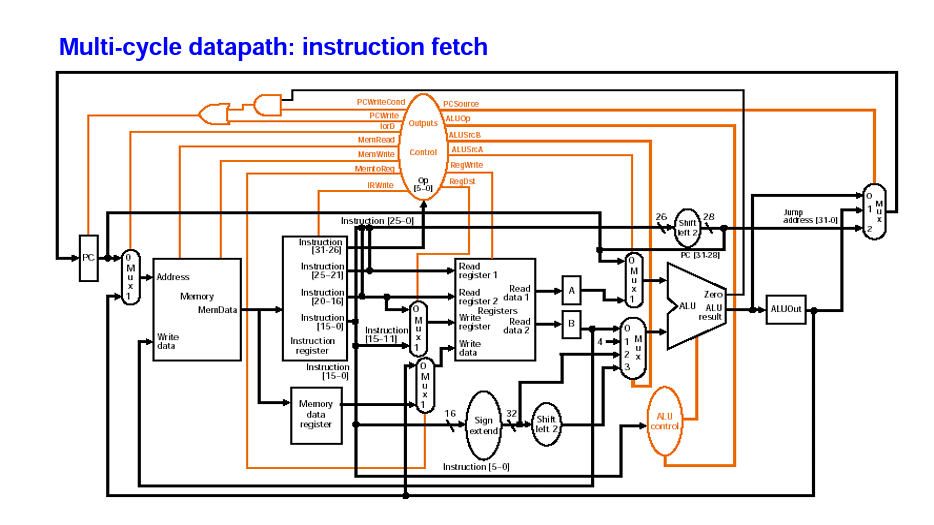
Single Cycle 구현에 비교했을 때 달라진 점
- ALU 3개가 합쳐져 ALU 수 감소 & ALU로 입력을 받는 MUX 추가됨
- multiple cycle에서는 하나의 명령어가 클럭의 경계를 넘어가므로 명령으로 사용할 instruction memory를 저장해야 한다. >> instruction memory를 저장할 플립플롭 추가됨.(A,B)
- ALU 계산값을 조합회로에 저장해야 하므로 ALUout 레지스터 추가됨
- Control unit은 state machine을 사용해 각 instruction에 따라 순차적 수행이 가능해지도록, state가 달라지도록 함
- 여러클럭에 걸쳐 사용되므로 instruction 메모리와 data메모리 하나로 합쳐짐
<첫번째 클럭>
I - Fetch
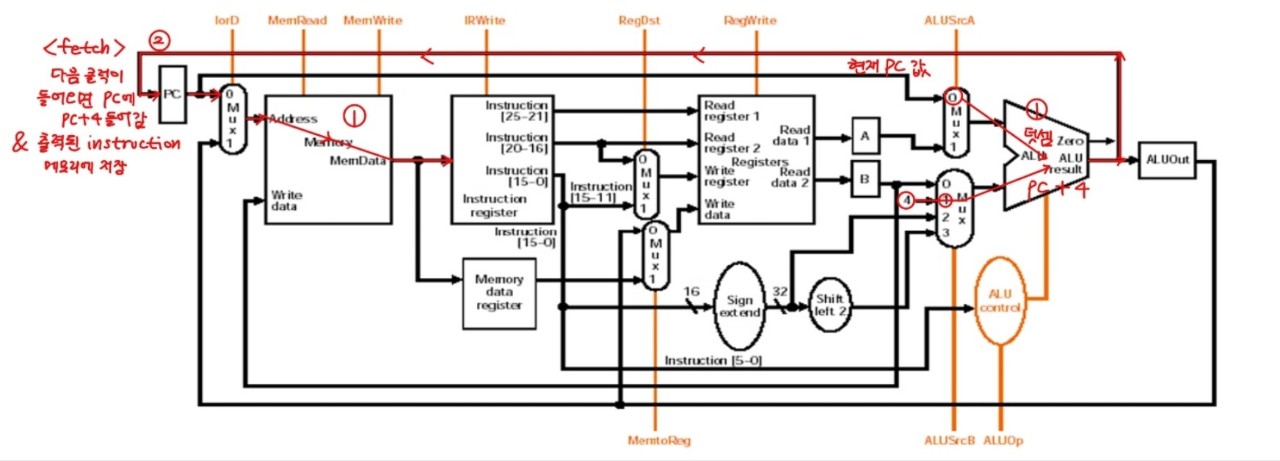
IR <- Memory[PC];
PC <- PC + 4 ;1.첫번째 클럭에서는 instruction Fetch가 일어난다. 메모리로부터 PC에 있는 4바이트를 끄집어내 instruction register로 집어넣어야 한다.
1.ALU에서 현재 PC값과 4바이트를 더한다.
2.다음 클럭이 들어오면 출력된 instruction은 메모리에 저장되고 PC에는 PC + 4 값이 들어가도록 한다.
<두번째 클럭>
I Decode, R - Fetch

A <- Reg[IR[25-21]];
B <- Reg[IR[20-16]];
ALUOut <- PC + (SignExtended(IR[15-0]) << 2);첫번째 클럭이 지나면 instruction 은 instruction register에 위치한다. 그 instruction을 끄집어내서 instruction decode한다.
1. IR 내부에서 reg1, reg2 지정하고 출력한다.
2.다음 클럭이 들어오면 플립플롭 A,B에 출력된 reg1,reg2값을 저장한다.
(1,2과정은 R-type일 때, Beq일 때 공통적으로 진행됨)
3.immediate값 가져와서 shift left2를 통과시킴 & PC값을 가져와 ALU에서 덧셈연산. 이 때 결과값은 ALUOut(Branch target address)
*Branch operation일 때 ALU는 branch destination을 계산하기 위해 사용된다.
<세번째 클럭>
Execution : 명령어가 R-type일 때, Load/Store일 때, Branch일 때 각각 다르게 진행된다.
- R-Type
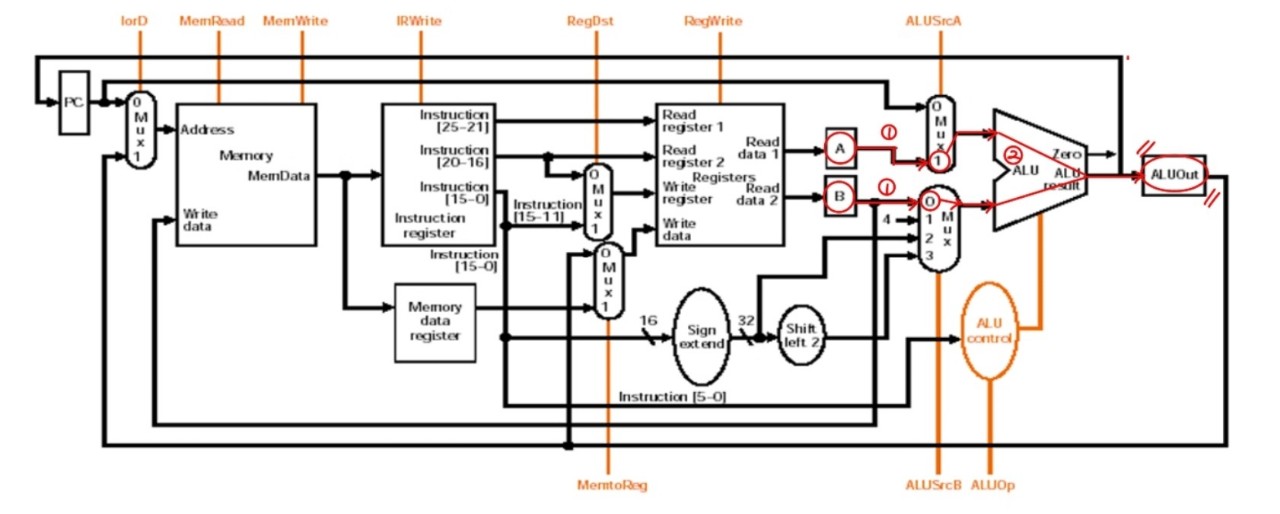
R type : ALUout <- A op B; // R type의 경우 두번째 클럭에서 꺼내온 reg1,reg2값 연산해서 ALUOut으로reg1 + reg2값 연산해 ALUOut에 저장
- I-Format

I-format load/store : ALUOut <- A+SignExtended(IR[15-0]); // 로드,스토어의 경우 로드/스토어 할 주소값 계산load / store할 메모리주소 계산해 ALUOut레지스터에 저장
- Branch

Branch : PC <- (A=B) ? ALUOut : PC + 4 ; // branch address로 jumpreg 1 - reg 2 가 0이면 PC + 4 로, 0이 아니면 PC + 4 + branch address로 점프
<네번째 클럭>
Completion : 명령어가 R-type일 때, Load/Store일 때, Branch일 때 각각 다르게 진행된다.
- R-Type

R-Format : Reg[IR[15-11]] <- ALUOut; // Rd지정해 주소지정ALU 연산한 결과 write data
- I-Format Load
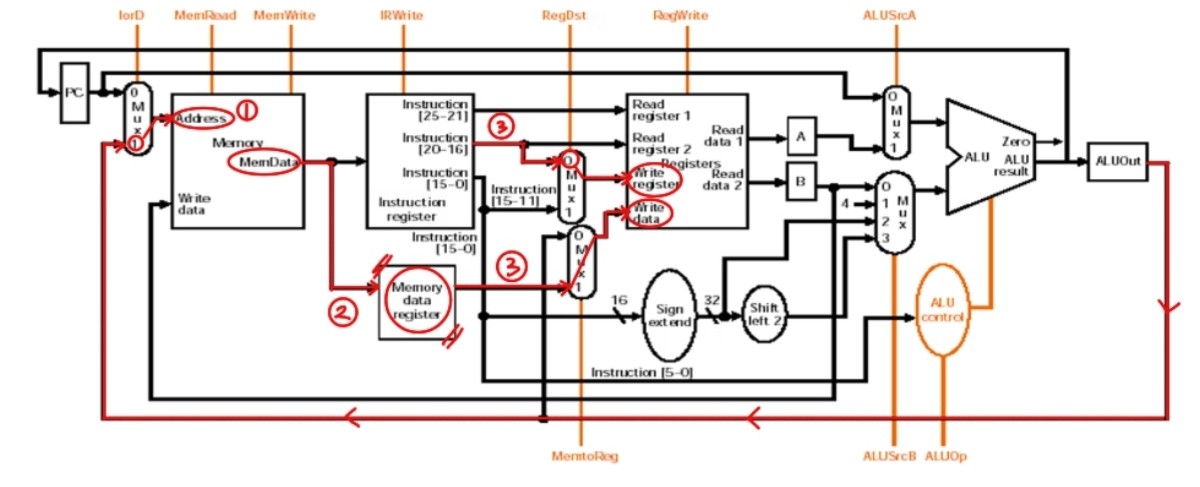
I-Format Load : MDR <- memory[ALUOut];1.3번째 클럭에서 ALUOut에 저장된 계산된 주소값을 메모리에 줌
2.다음 클럭 상승시점에 memory data register로 보냄
3.그 다음 클럭에 rt지정되고 memory data register로 보내진 값 레지스터로 보내 write data
- I-Format Store

I-Format Store : memory[ALUOut] <- B;1.3번째 클럭에서 ALUOut에 저장된 계산된 주소값을 메모리에 줌
2.플립플롭 B에 저장되어 있는 레지스터2값 끌어와 메모리에 write data
Multiple cycle implementation with everything
control unit을 추가해서 multiple cycle을 완성하면 다음과 같다.

single cycle의 조합회로 형태인 control unit과 다르게, multiple cycle은 제어워드를 만드는 순차회로 state machine으로 구성된다. instruction에서 operation 6비트를 가지고 state machine을 진행시킨다.
Finite state machine
control unit을 state machine으로 구현한 형태는 다음과 같다.

instruction 별 소요되는 클럭
| R-Format | 4클럭 소모 |
| Load | 5클럭 소모 |
| Store | 4클럭 소모 |
| Beq | 3클럭 소모 |
| Jump | 3클럭 소모 |
Load명령어가 5클럭으로 가장 클럭을 많이 소모하기 때문에 오래 걸린다.
single cycle을 사용했다면 Load 명령어 5클럭이 끝날 때까지 완료된 다른 명령어들은 기다려야 한다.
하지만 multiple cycle을 사용하게 되면 각 명령에 따라 제어가 달라지게 된다.
이미지 출처 : chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://www.cs.umd.edu/~meesh/cmsc311/clin-cmsc311/Lectures/lecture33/multi_cycle.pdf
chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://www.cs.umd.edu/~meesh/cmsc311/clin-cmsc311/Lectures/lecture34/multi_control.pdf
'컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] 4-4. Hazard (0) | 2022.11.14 |
|---|---|
| [컴퓨터 구조] 4-3. Pipeline Processor (0) | 2022.11.13 |
| [컴퓨터 구조] 4-1. Single - Cycle Processor (0) | 2022.11.12 |
| [컴퓨터 구조] 2-2. MIPS (0) | 2022.11.11 |
| [컴퓨터 구조] 2-1. ARM (0) | 2022.11.10 |



