
Kim Seon Deok
EfficientNet 본문
EfficientNet [ Mingxing Tan, Quoc V. Le]
Rethinking Model Scaling for Convolutional Neural Networks
conv 네트워크 모델의 크기를 키우는 방법 (accuracy & efficiency의 측면)
1. layer depth를 키우기
2. channel width를 늘리기
3. input image의 resolution을 올리기 >> 모델 architecture와 직접적으로 관련이 있지는 않다!
EfficientNet은 한정된 자원으로 이 3가지의 최적의 조합(constant ratio)을 compound scailing 방법을 통해 연구한 논문이다.
기존에 나온 모델들을 조금 더 효율적으로 하기 위한 고찰로부터 비롯
mobileNet
G pipe - 2018년 557M parameter로 84.3%의 accuracy를 달성 >> hardware memory limit에 부딪히게 되어 효율적인 모델을 고려하게 됨.

Model Scailing
기존 baseline모델에서 width, depth, resolution 관점에서 scailing을 적절한 비율로 조합해 compound scailing model을 만들어 내었다.
Depth(d) : 가장 흔한 scale-up 방법으로, 깊은 layer은 더 높은 성능을 낸다.
하지만 layer를 계속 깊게 쌓다보면 Gradient Vanishing problem현상으로 학습이 어렵다.
Width(w) : 대개 작은 크기의 모델들이 사용하는 방법
width를 넓게 할수록 미세한 정보(fine-grained feature)들을 더 많이 담을 수 있다.
하지만 깊이가 얕은 네트워크는 high level features를 얻는 것이 어렵다.
Resolution(r) : input으로 resolution이 더 큰 이미지를 넣으면 성능이 올라간다.
Compound Model Scailing
i : stage >> 한 layer
F : Activation fucntion >> i에 따라 자료 구조의 크기 및 activation function이 다를 수 있다.
L : F를 반복하는 횟수
X : 이들을 통합한 input 데이터
H, W, C : 입력 tensor의 Height, Width, Channel >> 3차원 이미지의 요소
최적의 layer architecture Fi만을 찾으려던 기존의 ConvNet과는 다르게,
Model scailing은 미리 만들어져 있는 baseline network를 변화시키지 않고(Fi를 고정) 제한된 상태에서 network length(L), width(W), resolution(H,C)만을 변화시키고자 함.
contant ratio

모든 layer를 constant ratio로 균일하게 scailing
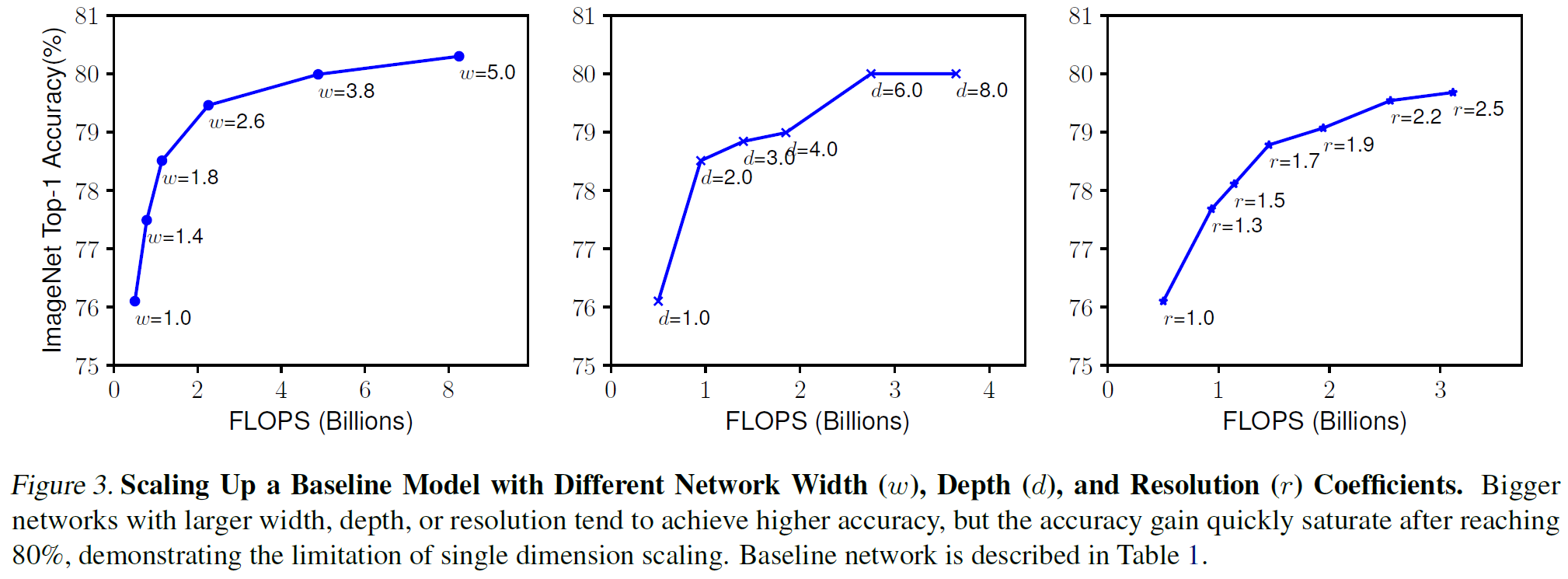
왼쪽부터 네트워크의 width, depth, resolution를 늘려가며 테스트를 진행함.
FLOPS : Floating point operations per second의 약자. '초당 부동소수점 연산'을 의미.
1초 동안 수행할 수 있는 부동소수점 연산의 횟수를 말한다. 즉 컴퓨터의 성능을 수치로 나타낼 때 주로 사용되는 단위.
w, d, r은 accuracy를 향상시키는 데에 기여하였으나, model이 커질수록 accuracy증가량이 감소했다. >> saturation
d : ResNet 101과 ResNet 1000은 비슷한 성능을 냄
w : 더 wide한 network는 더 세밀한 feature들을 잡아내고 train하기 쉽다. 하지만 extremely wide 하면서도 shallow한 network는 high level의 feature들을 잡아내는 데에 한계가 있다.
r : resolution이 높을수록 더 세밀한 pattern들을 잡아내기 쉽다.
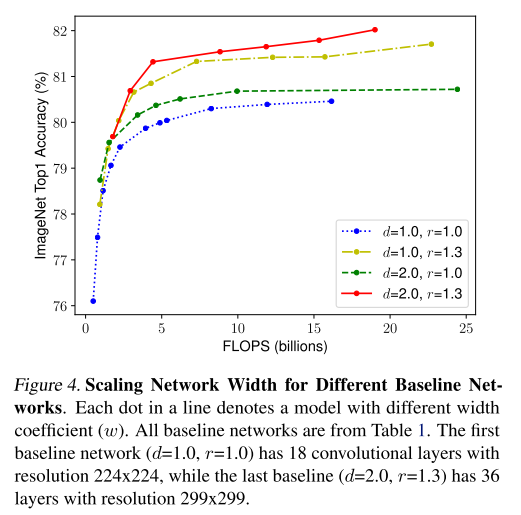
width를 고정한 채로 depth와 resolution을 변화시키면서 성능을 비교
네트워크가 깊어지고, 고해상도가 될수록 정확도가 향상되었다.
different scailing dimensions은 독립적이지 않고, convnet scailing 동안 width, depth, resolution의 balance가 중요하다.
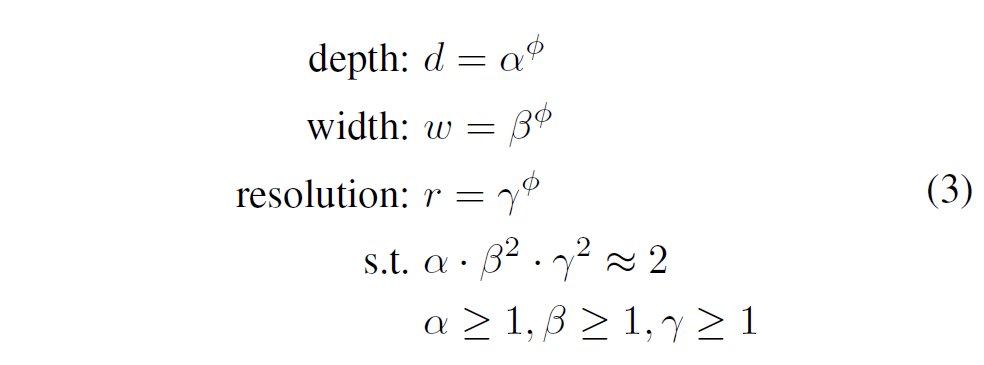
알파, 베타, 감마 : small grid search(NAS)에 의해 결정되는 고정된 상수값
파이 : 사용자가 model scailing을 하기위한 resource양을 조절해주는 compound coefficient
depth를 2배하면 flops가 2배로 증가한다. 반면 width와 resolution을 2배 증가하면 4배 증가하기 때문에
(한 layer에서 output으로 나갈 때 channel수가 2배가 되는데, 다음 layer의 input으로 들어가게 되면 또 2배가되므로 총 4배가 되는 것 + 가로 세로 size가 2배씩 늘어나면 연산량 4배로 늘어남)
Efficient 논문에서는 compound scailing method 로서, 상수 알파값과 베타, 감마의 제곱값을 2에 근사시키는 조건 하에서 가장 높은 성능을 낼 수 있는 width, depth, resolution 값을 찾도록 하는 식을 설계했다.
Baseline network를 만들어 주기 위해 MNasNet구조를 이용
특정 hadware device를 targeting하지 않으므로 Latency 부분은 포함x
compound coefficient 값인 파이 = 1일 때 알파 : 1.2, 베타 : 1.1, 감마 : 1.15인 상태가 최적
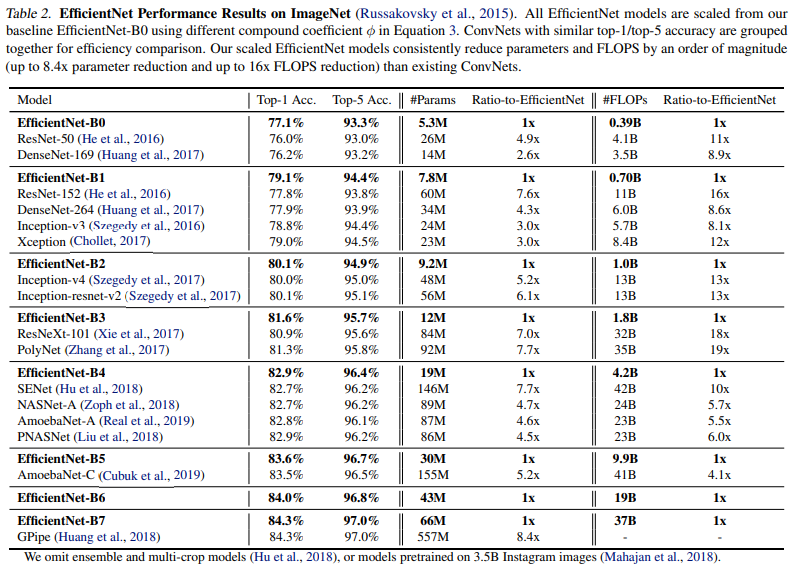
서로 다른 파이 값으로 scailing하며 EfficientNet을 B1에서 B7까지 만들어 성능 비교
B7이라 해서 파이값이 7인 것은 아님
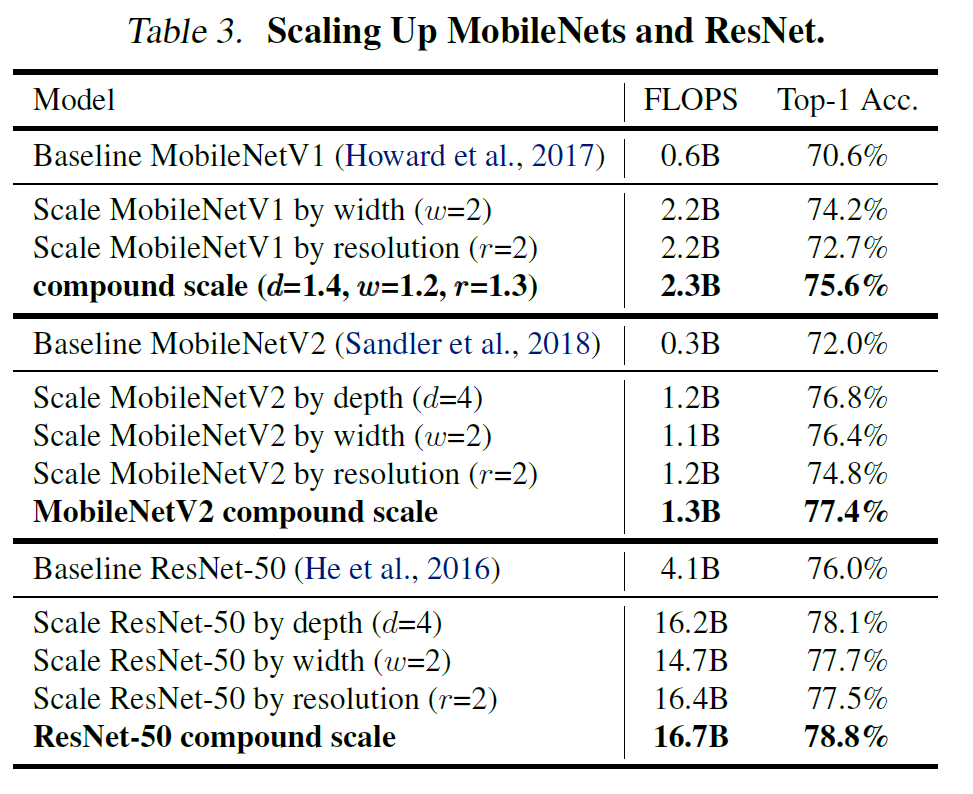
MobileNet과 ResNet에 Compound Scale을 적용한 결과, 기존의 FLOPS와 유사하면서 정확도가 증가한 것을 볼 수 있다.

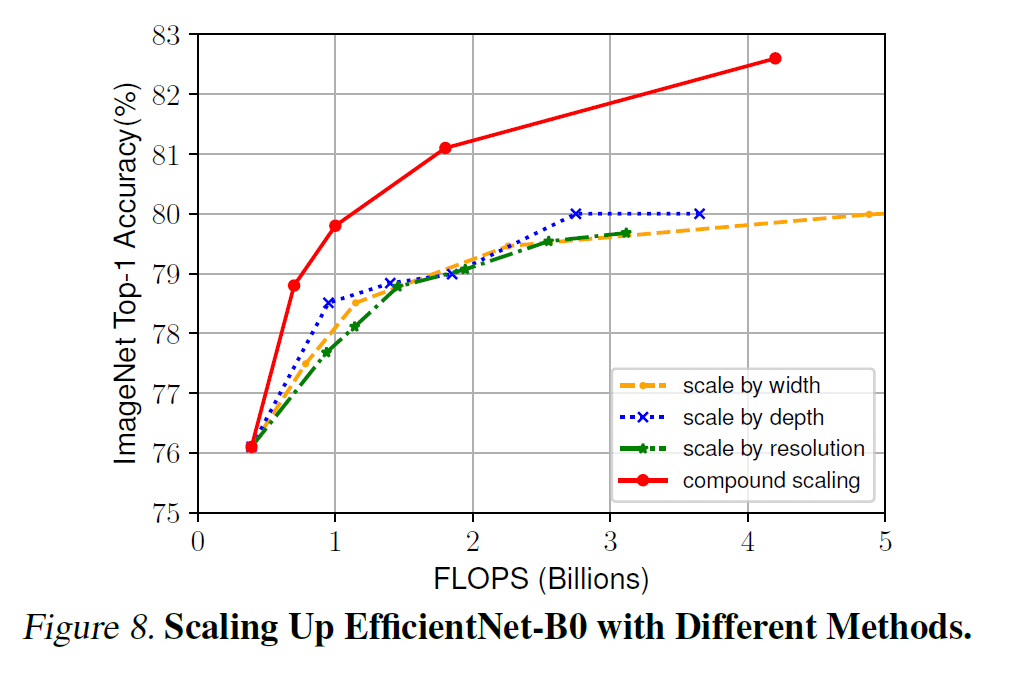
Compound scailing을 적용한 것이 성능이 제일 좋았음을 보여주는 그래프
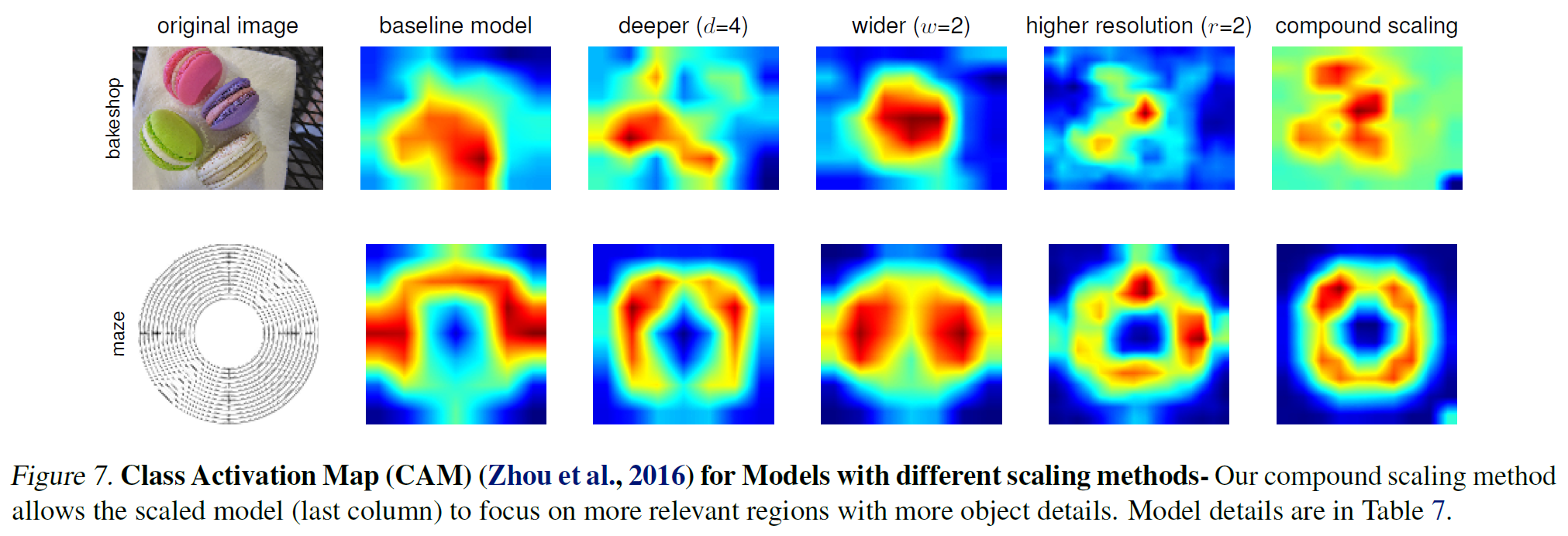
CAM : 이미지 내에서 어떤 부분이 활성화 되는지를 볼 수 있다.(빨간색 : 해당 class가 강하게 반응, 파란색 : 해당 class가 약하게 반응)
CAM 결과 역시 compound scaling을 적용한 것이 더 안정적으로 activation.
의의
기존 CNN Scaling 방법은 depth, width, resolution 중 하나의 요소를 고려했지만, 정확도와 효율성을 모두 챙기지 못했다.
한정된 자원을 갖고 있는 상황에서 Depth, Width, Resolution의 balance를 맞추어, 모델의 크기와 연산량을 줄이면서도 성능을 높일 수 있는 방법에서 대한 연구를 수행함으로써 accuracy가 높아졌으며 parameter수와 FLOPS가 더 작아졌다.
요약
1. 기존 baseline모델에서 width, depth, resolution scailing을 적절한 비율로 조합해 compound scailing model을 만듦.
단점
accuracy 증가량이 saturation되는 현상
제한된 상태에서 모델의 성능을 효율적으로 올리는 것이므로 성능 향상의 한계가 존재.
논문 리뷰 출처 : https://www.youtube.com/watch?v=Vhz0quyvR7I&feature=youtu.be


