
Kim Seon Deok
DenseNet 본문
DenseNet
https://arxiv.org/pdf/1608.06993.pdf
Densely Connected Convolutional Networks
CNN에 대한 많은 연구결과로부터 layer간 shortcut connection을 구성하면 convolution network가 상당히 깊어질 수 있고, 더 accuracy가 올라가며 학습시키는 데 매우 효율적이라는 것이 입증되었다.
ResNet의 shortcut connection에서 영감을 받아 이를 확장하여 cnn 구조를 바꾸는 시도를 함.
DenseNet은 ResNet과 많이 닮았다. 네트워크의 성능을 올리기 위한 접근방식이 비슷하다.
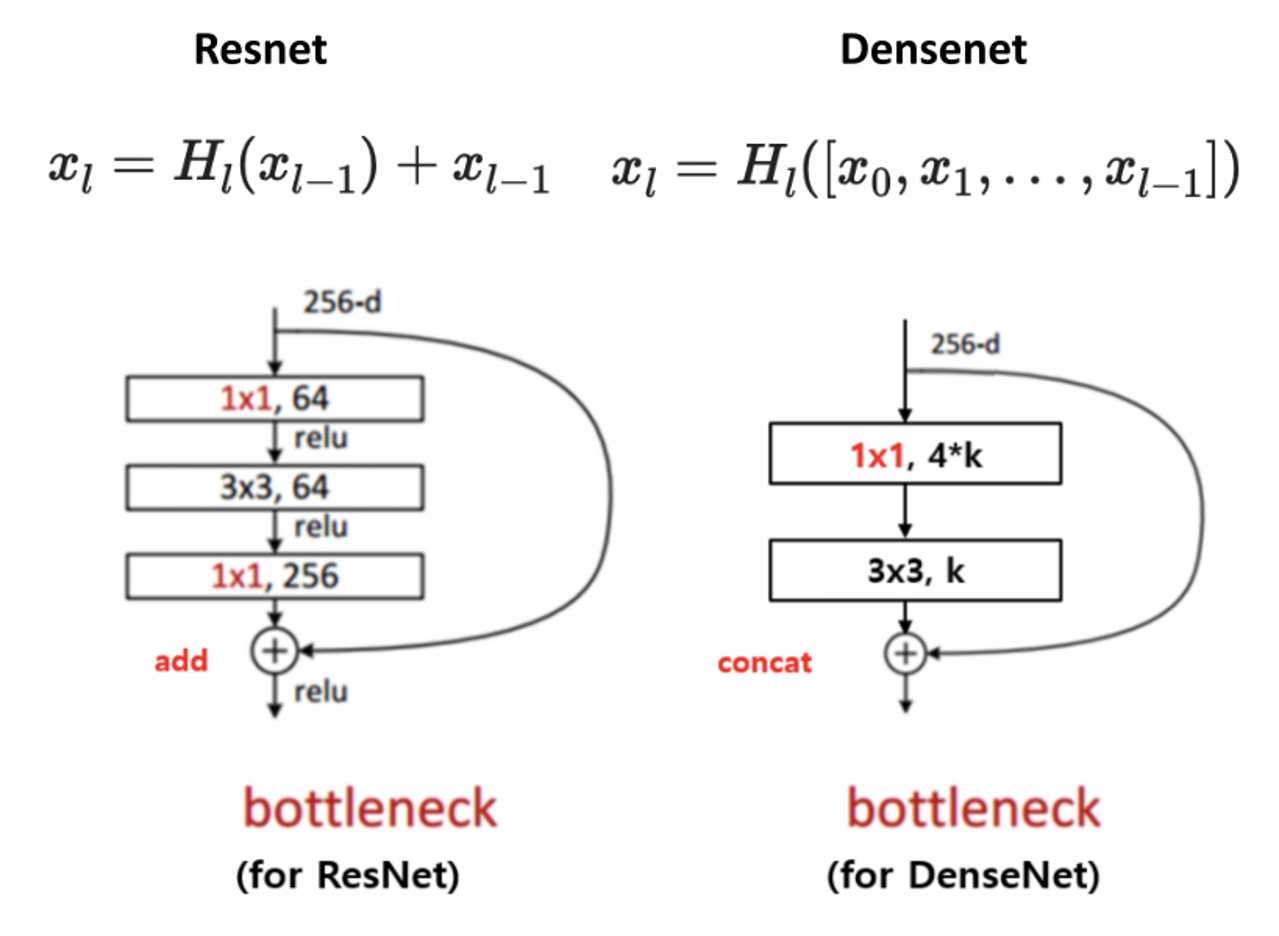
* ResNet의 Residual Block을 보면 convolution의 연산결과와 convolution연산을 거치지 않은 상태를 합하여 다양한 방식으로 gradient를 반영한다.
하지만 단순한 Residual Block에서는 계산량의 문제가 발생하게 된다. Residual Block을 계속 쌓게 되다 보니 파라미터가 계속 누적되어 계산량이 증폭되는 문제가 발생하게 된다.
따라서 Residual Block + Bottleneck을 사용하게 되었다. Bottleneck구조는 이전의 GoogleNet에서 차용한 것이다.

ResNet과 DensNet의 공통점
Skip Connection을 이용해 정보를 더 깊은 layer까지 전달할 수 있는 path를 만들어 학습이 잘 되도록 하였다.
기존의 ResNet은 바로 그 다음 layer에만 connection을 연결하기 때문에 L개의 layer가 있다면 L개의 connection만 가질 수 있었다. element-wise addition
DenseNet에서는 layer간 정보 흐름을 최대화하기 위해 모든 layer들이 서로 연결되게끔 구성했다. 이전 layer들로부터 추가적인 정보를 얻고, 그들 고유의 feature map을 그 다음의 모든 layer로 전달하는 형태이다. 따라서 L(L+1)/2개의 connection을 가질 수 있다. channel-wise concatenation
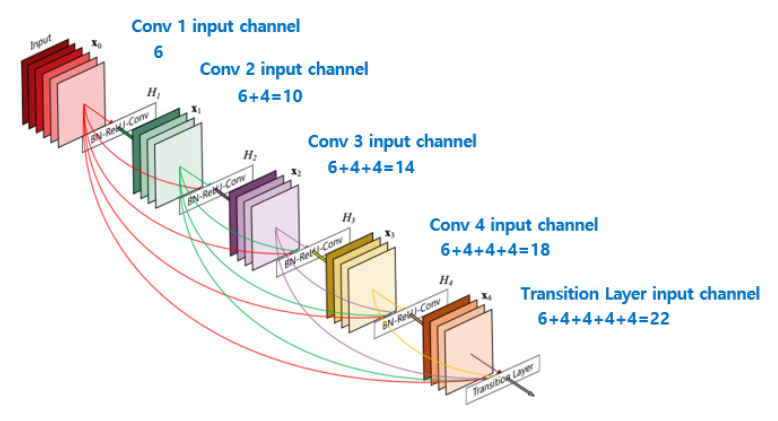
Growth rate
어떤 layer 이후의 모든 layer들을 전부 concatenate하게 되면 feature갯수가 급격하게 늘어나게 된다.
얼마만큼의 feature가 늘어날 지에 대한 값을 hyperparameter로 지정하면, 그 값을 통해 일정하게 등차수열의 형태로 feature 갯수가 늘어나는 것을 조절할 수 있다.
concatenation을 하기 위해서, 각 layer에서의 output이 똑같은 channel 수로 만들어 주어야 하는데, 이 때 굉장히 작은 output channel 수를 Growth rate(k)라고 한다.
concatenation은 모든 layer가 아닌 각각의 dense block에서 일어나며, 각각의 layer는 이전의 같은 dense block의 모든 layer의 feature map들을 input으로 받는다.
>> ResNet과 다르게 output feature의 channel이 더 커진다.
: conv network를 통과한 single image
: 번째 layer의 비선형 변환. 이는 BN, ReLU, Pooling, Conv로 구성된 composite function이다.
: 번째 layer의 출력
ResNet은 element-wise addition을 하여 덧셈이 이루어지므로, feature들을 단순히 더해줌으로써 output과 input feature channel이 같다.
x_{l} = H_{l}(x_{l-1}) + x_{l-1} >> l번째 layer는 이전 layer의 feature map만을 입력으로 받음.
기존 ResNet은 Residual Basic Block의 계산량 증가문제를 개선하기 위해 1*1 convolution으로 dimenstion reduction을 한 다음 다시 1*1 convoluion을 이용해 expansion을 하여 dimension이 축소되었다가 확대되는 구조인 Residual bottleneck 구조를 만들어냈었다.
DenseNet은 channel-wise concatenation을 하여 output feature의 channel이 커진다.
x_{l} = H_{l} ([x_{0}, x_{1}, ... , x_{l-1}]) >> l번째 layer는 모든 이전 layer의 feature map을 입력으로 받음.
DenseNet은 1*1 convolution을 이용해 dimension reduction을 하지만 expansion은 하지 않는다.
대신 feature들의 concatenation을 이용해 expansion연산과 같은 효과를 만들어 낸다.
Composite layer
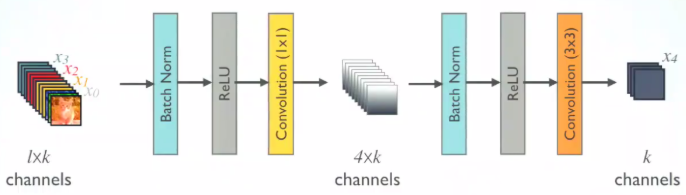
Batch Normalization - ReLU - Convolution으로 이루어진 구조
DenseNet - B : composite layer 가 bottleneck으로 이루어짐
Batch normlization - ReLU - Convolution(1*1) - channels - Batch normalization - ReLU - Convolution(3*3)
1*1 conv는 feature map에 대한 channel 수를 줄이고 4*k 개의 feature map을 생성.
3*3 conv는 다시 채널을 growth rate(k)만큼 줄임
Dense Block

-가장 처음에 사용되는 convolution 연산 : input image의 size를 Dense Block에 맞게 조절하기 위한 용도로 사용
Dense Block에 있는 layer들은 모두 같은 feature map size를 가진다.
compression
-Transition layer : feature map의 가로, 세로 사이즈를 줄이고 feature map의 개수를 줄이는 역할
Batch Normalization - ReLU - 1*1 conv - 2*2 aveage pooling 으로 구성
dense block이 m개의 feature map을 가지는 경우, θm개의 feature map으로 수를 줄임.
* ≤ 1 : copression factor
이면, feature map의 수는 바뀌지 않고 그대로 가져감.
θ<1 이 적용된 DenseNet을 DenseNet-C
bottleneck 및 이 모두 적용된 모델을 DenseNet-BC
논문에서는 θ = 0.5를 사용
-Classification layer : softmax함수를 사용해서 분류 >> fully connectied layer를 사용하지 않으면서 파라미터 수 감소

DenseNet-121 : (6*2)+(12*2)+(24*2)+(16*2)+5=121
Dense Block 4개로 이루어진 구조

아래 6개의 DensNet 중 위의 3개의 DensNet은 순수한 DenseBlock만을 사용, 아래 3개는 bottleneck layer와 compression을 동시에 적용한 DenseNet이다.
k = growth rate
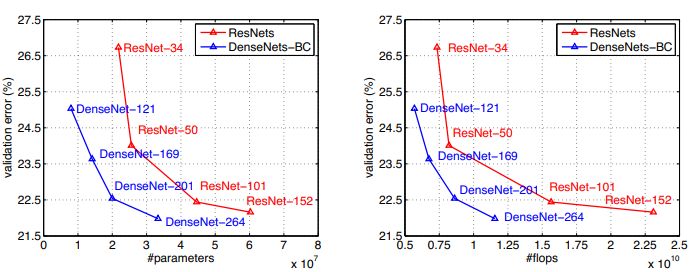
-depth가 깊어질수록 네트워크의 크기가 커지고 parameter수가 늘어난다.
-depth가 깊어질수록 에러율이 낮아진다.
-ResNet과 비교해보았을 때, DenseNet은 파라미터 수가 1/10이면서도 성능은 4.51로 훨씬 좋다.
Feature usage heat-map

가로축 : l번재 생성된 feature
세로축 : s 번재 생성된 feature
빨간색은 conv 가중치 절댓값이 1, 파란색 conv가중치 절댓값이 0을 의미
첫번째 행 : Dense Block의 입력 layer에 연결된 가중치를 encoding
검은색 박스 : transition layer & clasification layerdiagonal line : 자기 자신에게 미치는 영향을 나타내기 때문에 대부분 1에 가깝게 높게 나타난다.Dense Block 1 의 transition layer : 초기 레이어도 많은 영향을 미침
Dense Block 3 의 transition layer : 초기 레이어의 아웃풋보다는 나중 레이어의 아웃풋이 결과에 영향을 많이 끼침 >> 데이터 추상화로 인한 가까운 층 데이터의 영향을 집중적으로 받는다.
Conclusion
- 성능 저하 또는 overfitting 징후 없이 parameter 수가 증가함에 따라 정확도가 일관되게 향상되는 경향이 있다.
- 훨씬 적은 파라미터와 연산으로 더 좋은 성능을 나타냄.
- identity mapping , deep supervision 및 다양한 depth의 속성을 자연스럽게 통합한다.
- vanishing gradient 문제 감소
- feature propagation 재사용성 및 강화
의의
진화된 Skip connection과 bottleneck layers를 적용함으로써 주요 Feature만 가진 매우 깊은 네트워크를 학습하여 성능을 높였다.
ResNet과 비교했을 때 더 적은 파라미터를 이용해 더 높은 성능을 내었다.
feature의 재사용을 통해 네트워크의 성능을 높였다.
단점
- layer가 깊어질 수록 depth가 늘어나 연산량이 증가한다.
요약
- 입력값의 summation에서 concatenatation으로의 변화
- feature map은 각 층의 상태를 저장하므로 이전 단계의 결과를 저장하는 것이 유용함
- Bottleneck layer를 사용해 feature map의 수를 줄임 >> DenseNet-B
- growth rate를 parameter값으로 설정해 feature map의 수를 일정하게 만듦
- DenseNet Block의 transition layer에서 compression을 사용해 feature map의 수를 줄임 >> DenseNet - C
논문리뷰 참고 출처 : https://gaussian37.github.io/dl-concept-densenet/


