
Kim Seon Deok
ResNet 본문
ResNet [He et al,. 2015]


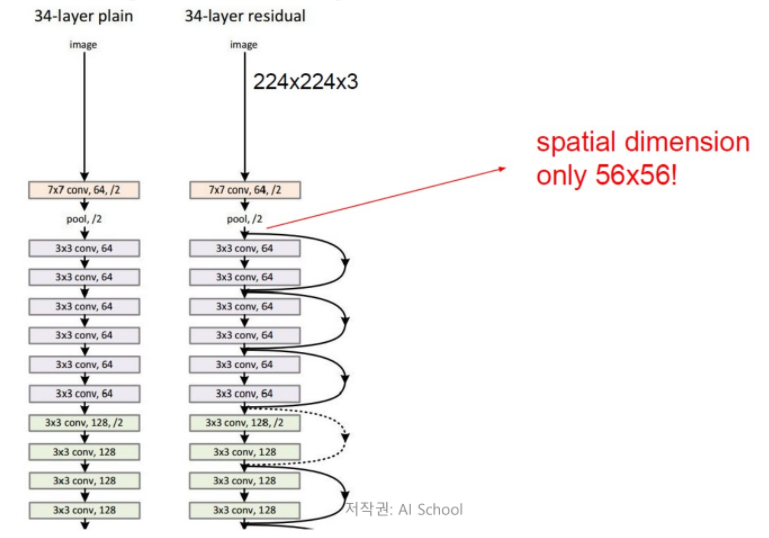
degradation problem : network가 깊어질수록 accuracy가 떨어지는(성능이 저하)문제.
1. vanishing gradient : 깊이가 깊어짐에 따라 많은 가중치값들이 소실되어 (작은 미분값이 0에 가까워짐)feature map이 점점 의미를 잃어가는 현상
2. exploding gradient : learning rate가 커짐에 따라 가중치값이 수렴하지 않고 발산하는 형태
overfitting : train data가 model에 과도하게 적합하게 학습된 상태 >> data로 인해 발생
degradation : 학습 과정에서 network가 깊어질 때 발생
Res : Residual(남은, 잔여의, 수학적으로 예측값과 실제값의 차이) >> residual connection / skip connection
residual을 copy해 connection시킴
residual connection을 이용해 이전의 impact있는 weight 정보를 이후의 layer까지 계속해서 넣어줄 수 있다.
backpropagate의 통로가 1개가 추가되므로 정보를 손실 없이 전달
deep residual learning framework(잔여학습)
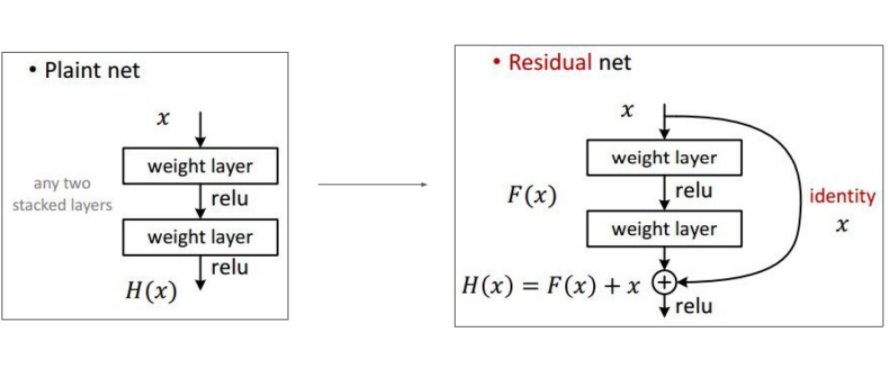
Plain net의 출력 : H(x) (original mapping) >> variance가 크다.
Residual net의 출력 : H(x) (residual mapping)= F(x) + x (재구성)
F(x) : H(x) - x 예측값과 실제값의 차이 >> reformation
F(x) = 0이 되도록 F(x)를 학습 >> 입력 x의 작은 움직임을 쉽게 검출할 수 있어, optimize가 더 쉬워진다
shortcut connection(identify mapping)
short connection을 추가하려면 더해지는 값 x와 output(F)의 차원이 같아야 한다.
identity mapping을 통해서, 최소한 한쪽의 gradient는 계속 흐를 수 있게 mapping 해줌으로써 vanishing gradient 와 exploding gradient 즉 degradation 문제를 해결할 수 있고, 더 좋은 accuracy가 나타난다.
input x가 model인 F(x)의 과정을 거치고, 자기자신인 x가 더해져 output으로 F(x) + x가 나오는 구조
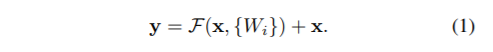
identity shortcut : 입력 x와 출력 y의 dimension이 같을 때 사용

projection shortcut : 입력 x와 출력 y의 dimension이 다를 때 Ws를 이용해 차원을 같게 해줌

Network Architecture

34층의 ResNet18은 처음 7*7 size의 convolution filter을 제외하고는 균일하게 3*3 size의 filter를 사용.
모두 동일한 feature map size를 갖게 하기 위해 모두 같은 수의 filter를 사용.
* x와 F를 같은 차원으로 만들어 주기 위해서 *
1. feature map size가 절반이 되면 filter 수는 두 배가 되도록 만듦.
2. dimension을 늘리기 위해 0을 넣어서 padding
3. linear projection

논문에서 이러한 현상이 gradient vanishing 때문은 아니라고 한다. 오히려 low convergence rate 때문데 나타난 현상이라고 나와있다.(수렴율(optimization에서 나타나는 기법. 수렴을 위한 epoch 또는 수렴난이도를 나타내는 척도)이 기하급수적으로 낮아짐)
층이 더 깊어질수록 수렴 속도도 빨라지고 에러율도 낮아졌다.

Deeper Bottleneck Architectures

1*1 Conv layer을 시작과 끝에 추가해 성능을 유지하면서 파라미터 수를 감소시킴.
channel을 줄였다가 잘 관찰하고 다시 원래 channel로 늘려주는 구조
Bottleneck구조는 Basic Block과 비슷한 표현력을 가지며 성능도 비슷하지만 훨씬 가볍다.
identity shortcut은 파라미터가 없으므로 bottleneck구조에 적합하다.
Basic block(33구조)을 지님 : ResNet 18, ResNet 34
Bottleneck block(131구조)을 지님 : ResNet 51, ResNet 101, ReNet 152
의의
이해하기 쉬우면서 모델의 성능을 크게 향상시킬 수 있었음.
초기단계에서 더 빠르게 수렴할 수 있도록 만들어 줌으로써 optimization을 쉽게 만들어줌
요약
1. degradation문제를 해결하기 위해 shorcut connertion을 이용해 F(x) 를 0으로 학습
2. short connection을 추가하려면 더해지는 값 x와 output(F)의 차원이 같아야 하므로 projection shortcut사용
3. Basic Block과 비슷한 표현력을 가지며 성능도 비슷하지만 훨씬 가벼운 Bottleneck구조 사용


