
Kim Seon Deok
VGGNet 본문
VGGNet논문 : https://arxiv.org/pdf/1409.1556.pdf
VGGNet

VGG논문은 convolutional network의 깊이를 증가시키면서 정확도 양상을 조사한다.
VGG모델은 3*3 convolution layer를 연속적으로 사용한 16-19 깊이의 모델이다.
Introduction
convnets이 컴퓨터 비전 분야에서 점점 상용화 되어가면서 더 좋은 정확도를 얻기 위해 AlexNet의 기본 구조를 향상시키기 위한 많은 시도가 이루어졌다. 이 논문에서는 Convnet 구조의 깊이에 집중한다. 이를 위해 더 많은 convolutional layer를 추가하였고 이것은 모든 layers에 매우 작은 3*3 convolution filters를 사용하였다.
ConvNet Configurations
ConvNet의 깊이가 증가함에 따른 성능 향상을 측정하기 위해 모든 conv layer의 파라미터를 동일하게 설정.
2.1 Architecture
ConvNet의 입력값은 고정된 크기의 224*224 RGB 이미지이다.
입력 이미지는 3*3 filter가 적용된 ConvNet에 전달되고, 또한 비선형성을 위해 1*1 convolutional filters도 적용한다.
(conv-conv-maxpooling = 하나의 VGG block. conv layer를 몇 번 반복할 것인지, filter 갯수를 몇 개를 쓸건지 결정해 비슷한 구조를 반복 )
일부 conv-layer에는 max-pooling(size = 2*2, stride = 2) layer를 적용한다.(maxpooling을 통해서 크기가 1/2로 줄어듦)
convolutional layers 다음에는 3개의 Fully - Connected layer가 있고, 첫 번째와 두 번째 FC에는 4096 channel, 세 번째 FC는 1000 channels를 갖고 있는 softmax layer이다. 모든 hidden layer에는 활성화 함수로 ReLU를 이용했다.
2.2 Configurations
서로 다른 모델 A~E. 11~19 범위의 깊이로 실험이 진행되었고, 넒이(channels)는 각 max-pooling layer 이후 2배씩 증가하여 512에 도달한다.

2.3Discussion
VGG모델은 전체에 stride = 1인 3*3 filter 사이즈만을 사용한다.
3*3 convolutional filter를 2개 이용하면 5*5 convolutional, 3*3 convolutional filter를 3개 이용하면 7*7 convolutional이 된다.
C개의 channel을 가진 3개의 3*3filter를 이용하면 연산량은 3*() = 27
3*3 filter를 여러 겹 이용하게 되면 1개의 relu 대신 2개, 3개의 relu를 이용할 수 있다.
parameter 수를 감소(x<0인 영역에서 relu함수값은 0이므로)시킬 수 있다.
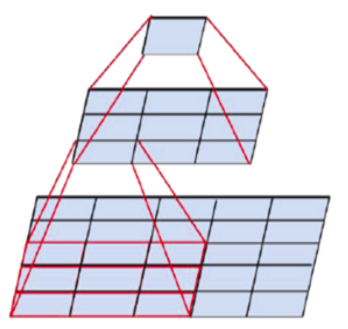
따라서 7*7 filter를 3개의 3*3 filter로 분해하여 파라미터 수도 감소시키고 더 많은 relu함수를 이용할 수 있게 된다.
data augmentation
VGG모델은 3가지의 data augmentation이 적용되었다.
1. crop된 이미지를 무작위로 수평 뒤집기
2.무작위로 RGB값 변경하기
3.image rescailing
3.2 Testing
test image를 다양하게 rescale하여 trained ConvNet에 입력으로 이용한다. 다양하게 rescale함으로써 성능이 개선되었다. 또 수평 뒤집기를 적용해 test set을 증가시켜주었고 최종 점수를 얻기 위해 동일한 이미지에 data augmentation이 적용된 이미지들의 평균 점수를 이용했다.
test image에 crop도 적용했다. 이는 더 나은 성능을 보였지만 연산량 관점에서 비효율적이었다.
4. Classification experiments
4.1 Single Scale evaluation
test set의 size가 S=256, 또는 S = 384로 고정된 단일규모 평가
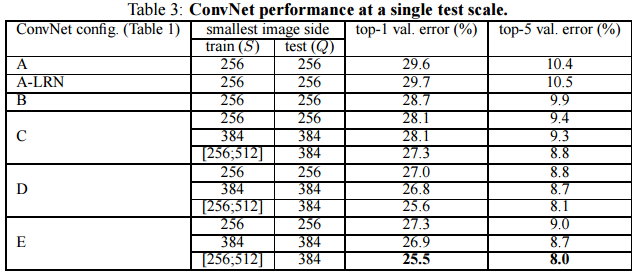
1. AlexNet에서 이용되었던 LRN이 효과가 없었다.
2. 깊이가 깊어질수록 에러가 감소했다.
3.다양한 scale[256-512]로 resize한 것이 고정된 scale의 training image보다 성능이 좋았다.
4. 1*1 conv filter를 사용한 C 모델보다 3*3 conv filter를 사용한 D 모델의 성능이 더 좋게 나왔다.
1*1conv filter를 사용하면 non-linearity를 더 잘 표현할 수 있지만 , 3*3conv filter가 spatial context의 특징을 더 잘 뽑아주기 때문에 3*3 conv filter를 사용하는 것이 더 좋다.
1*1 conv layer는 비선형성을 부여하기 위한 용도이다.
입력과 출력의 channels를 동일하게 하고 1*1 conv layer를 이용하면 relu함수를 거치게 되어 추가적인 비선형성이 부여된다.
1*1 conv filter의 의의
1.filter 수 조절
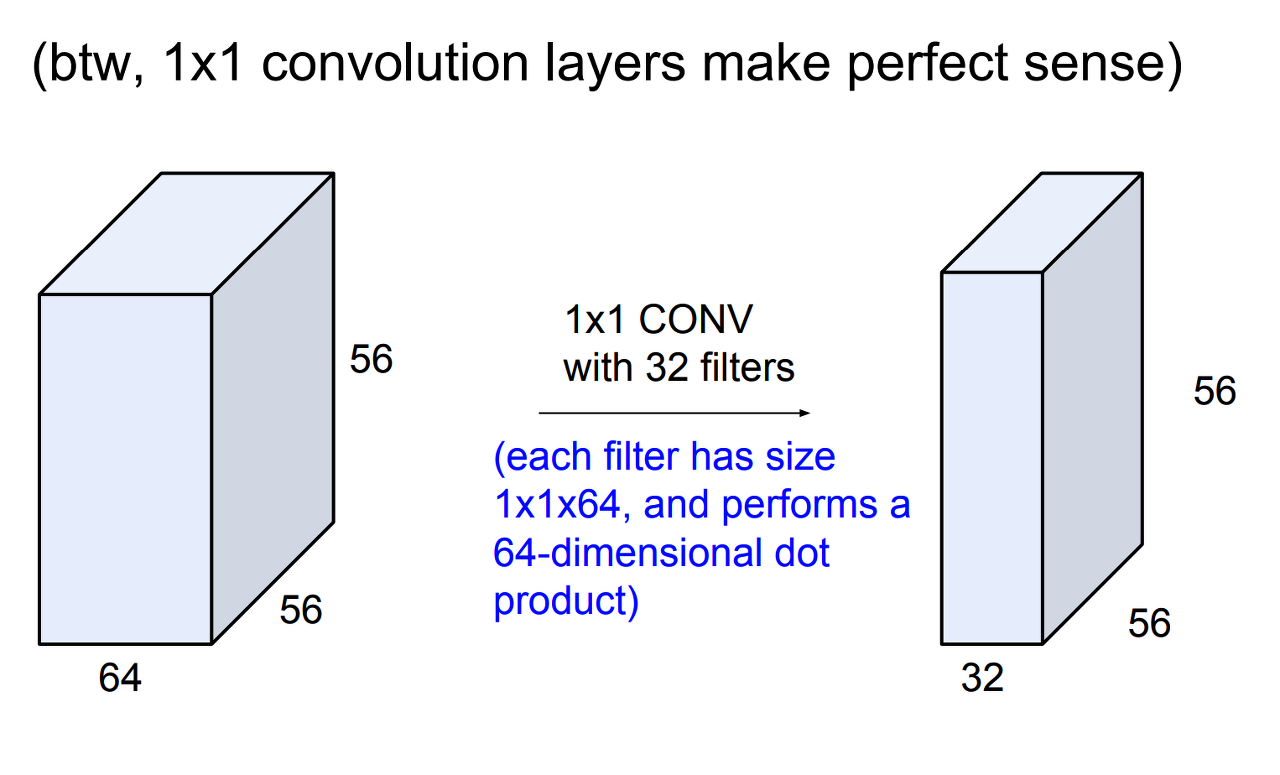
2.연산량 감소
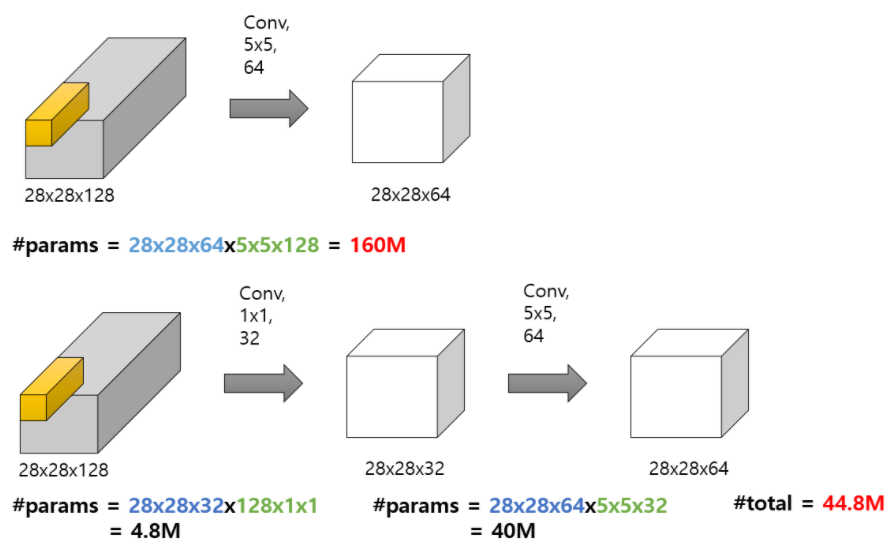
3.Non-lineartiy 증가
많은 수의 1*1 convolution을 사용했다는 것은 ReLU활성화 함수가 지속적으로 사용되었다는 뜻이고, 이는 모델의 비선형성을 증가시켜준다. >> 더 복잡한 문제를 해결하는 것이 가능해진다.
한계
파라미터 수가 매우 많다.
요약
-3*3 filter를 이용해 파라미터 수를 감소시키고, non-linearity를 증가시킴
-1*1 filter를 이용해 filter 수 조절, 연산량 감소, 추가적인 non-linearity를 줌
-layer가 깊어지고 작은 filter를 사용했음에도 불구하고 Conv연산이 대칭적으로 이루어지면서, 충분히 넓은 영역에 대한 feature를 잘 추출해냄.


