
Kim Seon Deok
밑바닥부터 시작하는 딥러닝 1 : 5장 - 오차역전파법 본문
5-1. 계산 그래프
오차역전파법 = 역전파(backpropagation)
가중치 매개변수의 기울기를 효율적으로 계산하는 방법
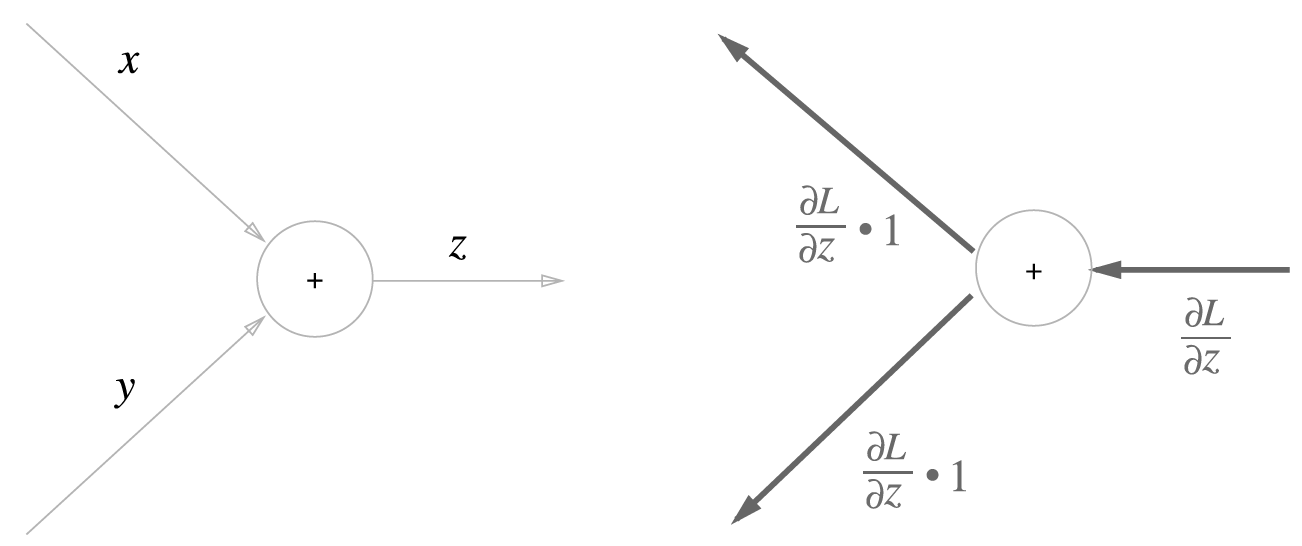
계산그래프 : 계산과정을 그대로 나타낸 것 - 복수의 노드와 에지로 표현
순전파(forward propagation)
계산그래프의 출발점 ~ 종착점으로의 전파
국소적 계산을 전파함으로써 최종 겨로가를 얻음

* 계산 그래프의 이점
국소적 계산을 통해 각 노드에서 단순한 계산에 집중해 문제를 단순화 시킴
중간중간 계산결과를 모두 보관할 수 있다.
순전파, 역전파를 통해 '미분'을 효율적으로 계산할 수 있다.
5-2. 연쇄법칙(chain rule)
합성함수 : 여러 함수로 구성된 함수
연쇄법칙 : 합성함수의 미분에 대한 성질

연쇄법칙의 원리 : 합성함수의 미분은 합성함수를 구성하는 각 함수의 미분의 곱으로 나타낼 수 있다.

import os , sys
sys.path.append()
import numpy as np
from common.layers import *
from common.gradient import numerical_gradient
from collections import OrderedDict
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01):
# 가중치 초기화
self.params = {}
self.params = ['w1'] = weight_init_std * np.random.radn(input_size, hidden_size)
self.params = ['b1'] = np.zeros(hidden_size)
self.params = ['w2'] = weight_init_std * np.randmo.randn(hidden_size, output_size)
self.params = ['b2'] = np.zeros(output_size)
# 계층 생성
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['w1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['w2'],self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
def predict(self,x):
for layer in self.layers.values():
x = layer.forward()
return x
# x : 입력 데이터, t : 정답 레이블
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y,t)
def accuracy(self,x,t):
y = self.predict(x)
y = np.argmax(y, axis = 1)
if t.ndim != 1:
t = np.argmax(t, axis = 1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x: 입력 데이터, t: 정답 레이블
def numerical_gradient(self, x, t):
loss_w = lambda w:self.loss(x,t)
grads = {}
grads['w1'] = numerical_gradient(loss_w, self.params['w1'])
grads['b1'] = numerical_gradient(loss_w, self.params['b1'])
grads['w2'] = numerical_gradient(loss_w, self.params['w2'])
grads['b2'] = numerical_gradient(loss_w, self.params['b2'])
return grads
def gradient(self,x,t):
# 순전파
self.loss(x,t)
# 역전파
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.valuees())
laysers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 결과 저장
grads = {}
grads['w1'] = self.layers['Affine1'].dw
grads['b1'] = self.layers['Affine1'].db
grads['w2'] = self.layers['Affine2'].dw
grads['b2'] = self.layers['Affine2'].db
return grads'AI > Deep Learning' 카테고리의 다른 글
| 밑바닥부터 시작하는 딥러닝 1 : 7장 합성곱 신경망(CNN) (0) | 2022.03.08 |
|---|---|
| 밑바닥부터 시작하는 딥러닝 1 : 6장 - 학습관련 기술들 (0) | 2022.03.08 |
| 밑바닥부터 시작하는 딥러닝 1 : 4장 - 신경망 학습 (0) | 2022.03.08 |
| 밑바닥부터 시작하는 딥러닝 1 - 3장 : 신경망 (0) | 2022.03.08 |
| 밑바닥부터 시작하는 딥러닝1 - 2장 : 퍼셉트론 (0) | 2022.03.08 |
'AI/Deep Learning' Related Articles
more




Comments