
Kim Seon Deok
VLIW(2) & Vector Processor 본문
VLIW - Loop-Carried- Dependencies
VLIW 아키텍쳐에서 loop unrolling은 main feature였다.
그리고 loop unrolling을 적용하다 보니 kernel of software pipelining이 필요해졌다.
for(i = 0 ; i < N ; i++)
{
A[i+2] = A[i] + 1;
B[i] = A[i+2] + 1;
}
LOOP: L.D F0, 0(R2) // 01
ADD.D F3, F0, F1 // 02
ADD.D F4, F3, F1 // 03
S.D F3, 16(R2) // 04
S.D F4, 0(R3) // 05
ADDI R2, R2, #8
ADDI R2, R2, #8
BNE R2, R4, LOOP
위 statement에서 A[i]와 B[i]는 double-precisoin FP number의 vector이다.
iterative loop인 for문에서 loop carried dependency를 확인 할 수 있다.
그 아래에 있는 LOOP문은 compile된 코드로 01~05는 iterative한 코드이다.
여기서 01-04 사이에는 loop carried dependency가 존재하고 RAW 해저드를 피하기 위해선 6 cycle이 필요하다.
따라서 3cycle마다 1 loop iteration을 실행해야 한다.

일반적으로 loop를 파이프라인화하기 위해서 컴파일러는 loop의 operation을 identify해야 한다.
그러고 나서 data dependency graph(DDG)를 빌드한다.
각 노드는 loop문의 OPeration이다.
각 엣지는 두 개의 register에 할당된 dependent한 operation과 memory operation을 연결한다.
각 엣지는 ( diff, min )으로 lable되는데 여기서
- Diff = 두 operation 사이에 있는 iteration 횟
- Min = RAW 해저드를 피하기 막기 위한 두 operation 사이에 있는 clock의 갯수의 최솟값
어떤 iteration이 schedule되는 지는 6 clock 당 2번 혹은 3 clock 당 1번이다.

O1-O4 간에는 loop carried dependency가 존재하기 때문에 O1은 O4가 실행을 완료하고 나서 실행되어야 한다.
만약 O1이 O4가 실행을 완료하기 전에 실행을 먼저 해버린다면, O1에 있는 값은 잘못된 값일 것이다.
따라서 O1과 O2 간, O2와 O3,O4 간에 empty slot을 할당해 주어야 한다.
따라서 software pipelining을 적용하면 위 슬라이드처럼 kernel이 만들어지게 된다.
kernel을 보면 empty slot이 매우 많은데, 여기서 kernel을 실행하기 위해서 VLIW는 LOOP에 break downㅇ르 consume해야 한다는 것을 알 수 있다.
VLIW는 간단한 하드웨어를 사용하기 때문에 매우 fancy한 아이디어이지만 software가 컴파일러에 의해 static하게 analyze되어야 하기 때문에 문제가 된다.
따라서 OoO 프로세스에서 처럼 instruction의 behavior을 dynamic하게 analyze할 수 없다.
또한 컴파일러는 application의 behavior를 anlayze해야 하므로 hardware의 detail한 정보가 필요하다.
software의 behavior은 different environment 혹은 different configuration에 의해 바뀐다.
Non-Cyclic Scheduling: Trace Scheduling
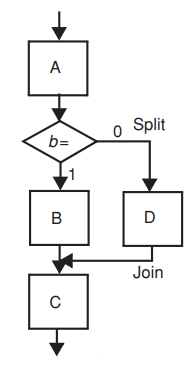
A,B,C,D는 basic block이다.
b라는 branch instruction이 존재하고 path가 diverge되기 때문에 이 instruction 결과에 근거해서 프로세스는 실행된다.
이전에 설명했듯이 basic block의 크기는 매우 작다
하지만 compiler optimization technique을 적용하기 위해서는 매우 큰 basic block이 필요하다.
따라서 이 execution에 instruction을 optimization하기 위해선 branch instruction의 behavior을 컴파일러로 analyze하는 방법이 있다.
대부분의 경우 A-B-C path가 실행된다.
그리고 매우 낮은 확률로 A-D-C path가 실행된다.
따라서 A-B-C를 하나의 very big basic block으로 보고 A-D-C를 split path로 보자
만약 split path를 실행한다면 D를 실행하기 이전에 B를 compensate하기 위한 instruction, -B와 같은 instruction이 우선적으로 실행되어야 한다.
마찬가지로 A-B-C를 실행한다면 B를 실행하기 이전에 D의 실행을 compensate하기 위한 instruction, -D가 필요하다.
-D 실행되고 나서 B가 실행될 것이다.
그러다 보니 이 execution은 이전의 speculative execution과 비슷한 매커니즘으로 돌아가고 있다는 것을 알 수 있다.
컴파일러는 code structure를 보고 branch instruction의 behavior을 estimate한다.
Conditional / Predicated instructions
Normal code
BNEZ R1, L1
MOV R2, R3
Predicated
CMOVZ R2, R3,R1
위 슬라이드의 normal code 처럼 high level code에서는 위 statement를 빈번하게 사용한다.
normal code에서
R1값이 0이 아니라면 L1으로 jump한다.
R1값이 0이라면 MOV instruction을 실행한다.
하지만 normal type의 statement의 문제점은 basic block의 크기가 매우 작다는 것이다.
predicated code에서
CMOZ가 있는데 이는 BNEZ와 MOV instruction을 combine한 것이다.
R1값이 0이라면 R2,R3에 대해 MOV를 실행한다.
- 이렇게 instruction이 combine되면 branch instruction이 제거된다는 장점이 있다.
앞서 보았듯이 branch instruction을 사용하면 execution path가 diverge되며 basic block의 크기 또한 매우 작기 때문에 VLIW 프로세서에서 문제가 되었다. 따라서 만약 predicated instruction을 사용하면 branch instruction을 제거할 수 있기 때문에 code scheduing 면에서 유리하다.
- 그리고 branch instruction을 제거함으로써 diverge instruction path를 제거할 수 있기 때문에 control dependency는 data dependency로 replace될 수 있다.
하지만 predicated instruction에는 단점도 존재한다.
- 모든 instruction들이 ask 되어야 한다. - normal code에서 predicated code로 combine될 때 2개의 instruction이 1개의 instruction으로 줄어들었다.
normal code에서는 특정 case에 있는 statement가 매우 large할 수도 있다.(= 한 state 당 많은 수의 instruction이 포함되었다라고 보면 됨) 그렇기 때문에 case를 skip하게 된다면 매우 많은 수의 instruction을 skip할 수 있게 되는 것이다.
하지만 predicated instruction을 사용한다면 항상 포함된 branch instruction의 결과값을 필요로 하게 된다.
따라서 predicated instruction은 오직 short skip(=각 state 당 할당된 instruction이 적은 경우를 말함) 일 때에만 유용하다.
- predicated instruction을 구현하기 위해선 복잡한 하드웨어 구조가 요구된다.
- predicated instruction을 사용하면 exception을 handle하기 어려워진다.
CMOVZ R2, R3, R1에서 R2, R3는 R1이 true인 경우에만 activated된다.
즉 condition인 R1이 true일 때에만 exception을 detect하게 된다.
Compiler Speculation with Hardware Support
VLIW 아키텍쳐의 또 다른 challenge는 compiler speculation이다. 이는 hardware적인 speculation과 유사하다.
hardware speculation은 software를 사용해서 implement 될 수 있다. -> software scheduling
code size가 증가되고 더 큰 basic block을 사용할 수 있게 되면서 더 복잡한 컴파일러 optimization을 적용할 필요가 생기게 되었다.
컴파일러는 branch instruction 위로 instruction을 옮겨서 branch condition을 판단하기 이전에 해당 instruction이 실행되도록 한다. 이렇게 되면 schedule할 수 있는 code sequence가 길어지고 ILP가 더욱 증가하게 된다.
Preserving Exceptions
precise exception은 프로세스에서 매우 difficult한 문제이다.
토마술로 알고리즘에서는 speculation으로 precise exception을 구현할 수 있었다.(commit stage처럼 stage 1개가 더 추가되어 있었음 - ROB)
precise exception은 또한 poison bit을 사용해서 implement될 수 있다.
LW R1, 0(R3)
BNEZ R1, L1
LW R1, 0(R2)
J L2
L1: ADD R1, R1, #4
L2: SW 0(R3), R1
위 코드에서 branch instruction인 BNEZ를 기반으로 이후에 나오는 LW, J는 skip될 수 있다.
또한 basic block의 크기가 매우 작기 때문에 VLIW 프로세서의 성능에 좋은 영향을 미치진 못한다.
따라서 LW는 BNEZ 이전에 실행되도록 speculative하게 위치를 옮길 수 있다.
그리고 exception은 LW에서 일어나게 된다.
LW R1, 0(R3)
LW.s R14, 0(R2)
BNEZ R1, L1
CHECK.s R14, repair
J L2
L1: ADD R14, R1, #4
L2: SW 0(R3), R14변경된 코드에서 basic block은 매우 커졌다.
exception은 LW.s에서 발생하고 BNEZ에 기반해 LW는 speculative하게 실행된다.
또한 poison bit을 사용할 수 있다.
poison bit : speculative execution을 핸들링 하도록 도움,
.s가 붙어있기 때문에 컴파일러는 이를 speculative execution이라 인식하고 instruction을 실행한다.
BNEZ가 not taken이라면 CHECK.s가 실행될 것이다.
Speculative Memory Disambiguation
컴파일러는 memory disambiguation을 support한다.
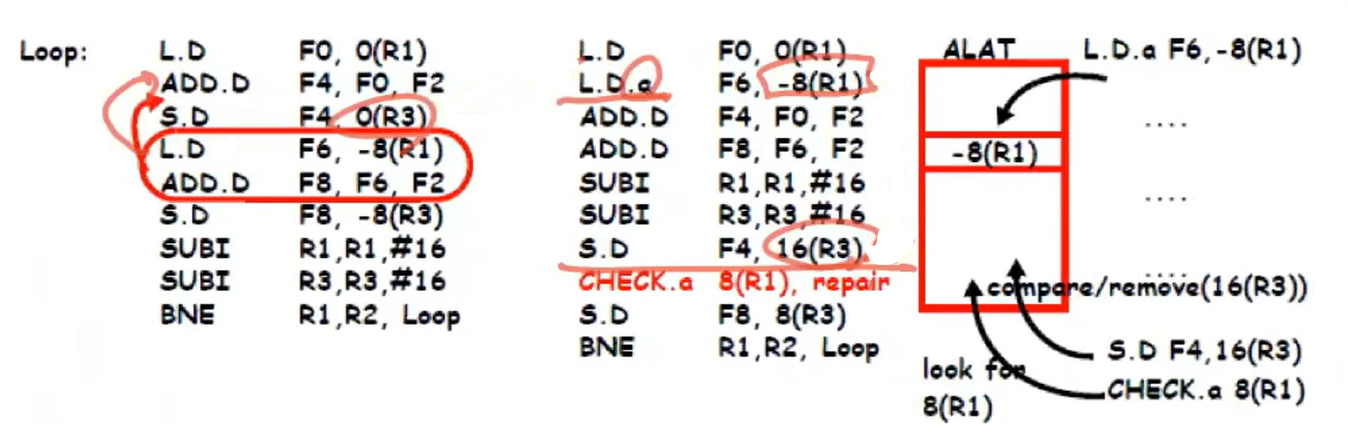
L.D를 S.D 위로 옮겨서 L.D.a가 speculative하게 실행될 수 있다.
S.D instruction이 실행되기 전까지는 store instruction의 실제 address값을 모르기 때문에 S.D instruction은 SUBI 아래로 옮겨진다.
S.D의 16(R3)가 L.D.a의 address인 -8(R1)과 같다면 CHECK.a repair 코드를 실행한다.
Vector Processors
vector processor는 superscalar processor 이전부터 사용되었고 multimedia (streaming)application에서 주로 사용된다.
vector processors의 가장 큰 특징은 vector data를 사용한다는 것이다.
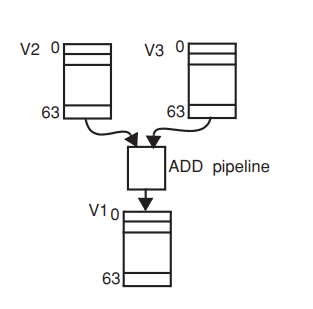
VADD V1, V2, V3
위의 명령어에서 v1 v2 v3는 동일한 type과 length를 가진 vector resgister이다.
v2 v3에서 각 element는 vector register에서 sequential하게 fetch된다.
ADD unit은 vector register의 각 element를 serial하게 fetch해오고 add operation이 각각의 element에 적용되어 serial하게 execute된다. 이 operation이 vector instruction에 적용되면 total cycle은 63(# of elements) + 10(# of stages) = 73 cycle이 된다.
for(i = 0 ; i < num ; i++)
{
array[i];
}
위의 루프는 빈번하게 array data를 사용한다.
따라서 array instruction을 다루기 위해서 반복적으로 loop의 코드가 array data에 access하도록 해야한다.
하지만 여기서 문제는 루프 내 코드가 프로세서에서 sequential하게 실행된다는 것이다.
iterative loop를 implement하려면 branch instruction이 필요한데 이는 프로세서 성능에 좋지 않다.
v1[i] <- v2[i] + v3[i]
index i 에 의해 V2, V3는 반복적으로 액세스 된다.
두 vector에서 연산한 결과값을 v1에 저장한다.
VADD v1, v2, v3
VADD v4, v1, v5위에서 처럼 각 명령어는 73 cycle이 걸렸다.
그리고 v1 vector register에서 data dependency가 존재하고 pipeline stage가 10일 때
프로세서에서 required data가 준비된 상태라 해도 다음 instruction에서 사용되지 않을 수 있다.
-> 프로세서에서 i=63 vector instruction의 결과값을 갖고 있어서 v1[63]이 ready상태라 해도 next instruction에서 사용되지 않을 수 있다.
vector processor
각 element가 sequential하게 fetch되고 execute된다.
array processor
각 array가 parallel하게 실행된다. -> SIMD와 유사하다.
vector processor의 advantage
- vector processor는 entire vector에 대해 instruction을 실행할 수 있다.
- code structure 가 매우 간단하기 때문에 성능을 매우 향상시킬 수 있다. -> inst fetch, decode, issue를 줄임
- vector component의 operation은 independent하다. -> data forwarding, data hazard detection, stall, control hazard, flushing이 발생하지 x
vector processor의 disadvantage
- 프로그램을 vector code로 transform해주기 위해 컴파일러가 sofisticate하게 작동해야 한다.
- 한정된 application에만 applicable하다. -> 특정 operation만 accerelate할 수 있다.
scatter / gather
vector processor의 문제점은 sparese data를 갖고 있다는 것이다.
- multimedia data에서 array의 각 element는 많은 수의 non zero value를 갖고 있다 -> dense하다
- normal data에서 array의 각 element는 많은 수의 zero value를 갖고 있다. -> sparse하다
만약 VADD v1, v2, v3 에서 v2 v3 element 값이 모두 zero value라면 v1 역시 zero value이다.
VMUL v1 v2 v3에서 v2 v3 값이 둘 중에 하나라도 zero value라면 v1 역시 zero value이다.
이 zero value를 meory에 저장하거나 compuation에 사용하게 될텐데, zero value가 너무 많으면 hardware resource가 낭비되게 된다.
따라서 non zero data에 한해서만 indexing the location of data를 함으로써 non zero memory value store하도록 한 다음 이 값을 computation에사용해야 한다. 이 과정을 scatter / gather 테크닉이라 한다.
때때로 matrix연산을 수행할 때 zero data를 특정 element에 할당하는데, matrix가 memory에 저장되어 있다면 zero data도 memory에 저장되게 된다. 여기서 computation을 수행하려면 메모리에서non zero data값 만을 필요로 하게 되므로 non zero data만을 가리키는 액세스를 수행해야 한다.
따라서 sparse data에 대한 vector operation을 수행할 땐 scatter gather 테크닉을 수행한다.
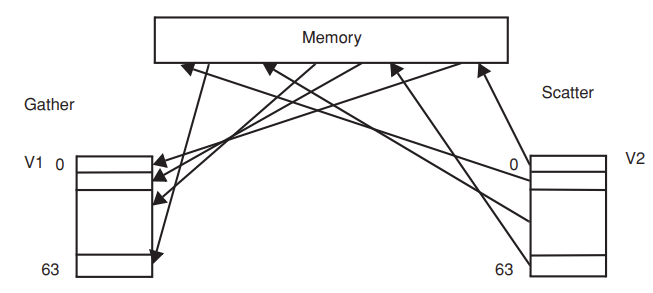
memory에 large array가 저장되어 있는 상태이다. 이 large array에는 zero data가 많이 포함되어 있다.
non zero data만 vector register에 저장한다음 vector computation에 사용하기 때문에 memory access pattern은 매우 복잡해진다. -> memory system의 bandwidth는 memory access에 의해 wasted될 수 있다 -> memory system의 congestion 일으킴
Gather : indexed address에 있는 memory component들을 load해와서 vector register에 consecutive하게 저장한다.
Scatter : vector register에 consecutive하게 저장된 data를 indexed address에 있는 memory에 store하는 작업이다.
scatter / gather을 통해 memory system의 waste를 막을 수 있다.
vector 프로세서는 OoO프로세서, VLIW 보다 간단하며 SIMD에 많이 활용된다 -> ex) GPU, DSA
'Advanced computer architecture' 카테고리의 다른 글
| VLIW(1) (0) | 2024.02.02 |
|---|---|
| register renaming, superscalar (0) | 2024.01.26 |
| Speculative executions (0) | 2024.01.19 |
| Static pipeline with out-of-order execution completion(2) (0) | 2024.01.11 |
| Scoreboarding (0) | 2024.01.08 |


