
Kim Seon Deok
Static pipeline with out-of-order execution completion(2) 본문
Static pipeline with out-of-order execution completion(2)
seondeok 2024. 1. 11. 23:19
Precise exceptions
Out-of-order completion의 주요한 단점은 바로 precise exception을 implement하기가 어렵다는 것이다.
ADD.S F1, F2, F1
LW R2, 0(R1)
두 instruction은 independent (각각 floating point inst, integer inst)
ADD.S instruction은 floating point add를 수행 -> IF ~ WB 까지 9 cycle (EXE : 5 cycle)
LW instruction은 integer add를 수행 -> IF ~ WB 까지 5 cycle (EXE : 1 cycle)

case 1 ) precise exceptions
LW instruction은 C6에 WB를 수행하고 integer register file는 업데이트되어 완료된다.
ADD.S instruction은 C6에 EXE stage를 마치지 못하고 진행 중인 상태이다.
만약 C7에서 ADD.S가 exception을 일으켜서 WB stage(C9)까지 숨긴다고 했을 때 exception이 발생한 시점 C7에서 LW instruction은 이미 모든 stage를 complete(C6)한 상황이므로 R2값은 업데이트 되어있는 것이다.
C9까지는 exception을 처리해야 하므로 이 때까지 업데이트 된 R2값을 사용하기 때문에 integer register file의 exception q발생 이전과 이후 상태가 다를 수 있다.
이러한 점들로 OoO completion에서는 precise exception을 구현하기가 어렵다.
이 precise exception의 문제점을 개선한 방법으로 exception을 hazard 처럼 다루는 방법이 있다.
case 2) exception = pipeline hazard
instruction이 pipeline을 따라 진행되기 전에 exception 여부를 확인해서 exception을 일으키지 않는 instruction은 진행을 시키지만, exception을 일으키는 instruction은 ID stage에서 stall하도록 하여 following 하는 instruction들도 모두 stall되도록 하는 방식이다.
하지만 이 방식 역시 instuction이 다음 stage로 진행되려면 이전 instruction들이 모두 complete되길 기다려야 하기 때문에 pipeline의 효율성이 떨어지게 된다.
case3) force in-order traversal of WB stage
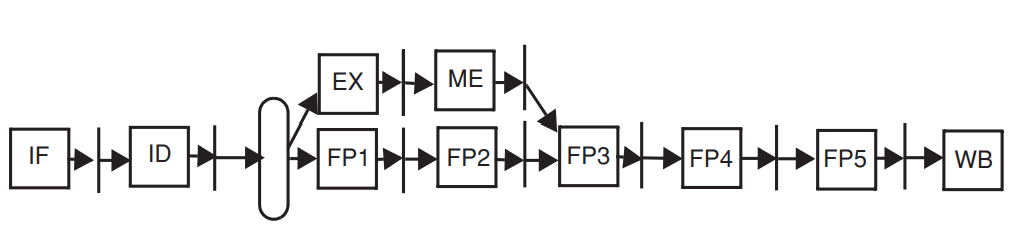
instruction이 exception이 발생하는 WB stage를 in-order로 force하는 방법이다.
WB stage에서 EXE 결과가 register에 기록되는데, 모든 instruction이 프로세스 순서에 따라 WB stage를 sequential하게 통과하도록 force하는 것이다.
위 그림에서 EX를 FP1과 merge, ME stage를 FP2 stage와 merge해서 명령어가 순서대로 모든 stage를 통과하게 한다.
integer instruction path에서만 보았을 때 EXE stage에 1stage를 더 추가해서 clock rate를 늘린다. 이렇게 되면 forwarding path가 늘어나게 된다.
따라서 instruction의 completion order를 엄격하게 컨트롤해서 exception 처리를 안전하게 관리하려는 방식이다.
Superpipelined CPU
superpipelined는 기본적인 5-stage pipeline의 각 stage 중 한 stage가 1cycle 이상 걸리게 되는 것을 말한다.

위 그림에서는IF, EXE, MEM stage에서 각각 1 stage 씩 추가되어 clock rate를 증가시키고 있다. (2 pipeline stages)
latency가 증가하기 때문에 대체 CPI가 증가하게 된다.
| Functional units | Latency | Inintiation interval |
| integer ALU | 1 | 1 |
| load | 3 | 1 |
| FP operation | 4 | 1 (pipiline화 되지 않으면 5) |
integer type instruction인 branch instruction의 경우 EXE2 stage에서 result가 나오고 이 때 result가 false라면 IF1~EXE2 까지의 instruction을 모두 flush해야 한다. 따라서 penalty로 3 clock을 waste하게 된다.
superpipieline CPU는 5-stage pipeline에서 bottleneck이 발생하여 걸리는 cycle보다 더 빠르게 동작한다.
각 pipeline stage를 pipeline화 하기 때문에 instruction throughput을 증가시킬 수 있다.
Superscalar CPU
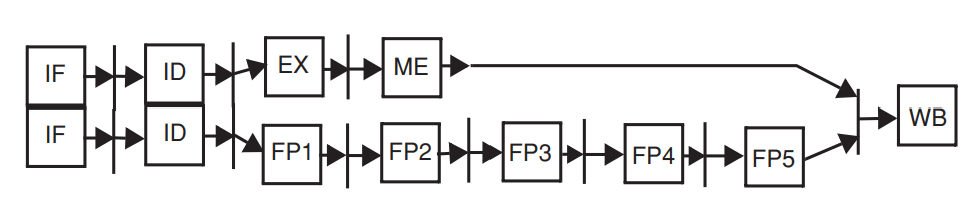
superscalar는 1 cycle에 2개 이상의 instruction이 fetch되고 decode되며 issue될 수 있음을 의미한다.
ideal하다면 IPC 는 2배가 된다. -> 성능이 2배로 증가
매 cycle 마다 2 개의 instruction을 fetch 해야 하므로 instruction fetch engine이 추가로 필요하다,
fetch 된 instruction 중 하나는 integer instruction, 나머지 하나는 floating point instruction이다.
이는 (INT, FP)로 그룹화된다.
하지만 일반적인 경우 integer type의 instruction과 floating point type의 instruction 갯수의 balance가 비슷하기가 쉽지 않기 때문에 컴파일러는 (INT, FP) 쌍을 찾기가 매우 어렵다. 그렇게 되면 available한 instruction pair를 찾을 수 없게 되기 때문에 이는 superscalar cpu의 문제점이다.
Static Branch Prediction
static pipeline architecture -> static branch prediction 적용 -> branch instruction 결과를 one direction으로 예측한다.
static microarchitecture의 문제점은 모든 branch가 always untaken이라는 것이다.
- taken : PC는 target branch로 변경됨
- untaken : instruction은 sequential하게 수행됨
branch prediction은 hardwired이며 컴파일러가 이를 통제할 수 없다,
loop의 마지막 branch는 대부분 잘못 predict되며 이로 인해 2cycle의 penalty가 발생한다.
hardwired branch prediction은 software에 의해 영향을 받지 않기 때문에 가장 static한 prediction 방식 중 하나이다.
code profiling
하지만 컴파일 타임에 컴파일러가 prediction을 컨트롤 하는 것도 가능하긴 하다.
컴파일러는 특정 input set에 대한 특정 코드의 실행을 simulation하고 코드 내 각 static branch에 대한 predict를 최적으로 수행할 수 있다.
이 prediction은 branch instruction에 hint bit으로 1bit를 추가하여 진행된다. 따라서 taken/not-taken prediction이 더 flexible해진다.
Static instruction scheduling
hardware는 코드 실행 순서를 dynamic하개 reorder하는 매커니즘이 없다.
instruction의 실행은 컴파일러에 의해 지시된 static한 process 순서에 따라 스케줄링된다.
그렇기 때문에 하드웨어는 코드 실행 순서를 dynamic하게 조정할 수 없으므로 컴파일러의 도움이 필요하다.
-> pipeline이 static한 이유
compiler가 코드를 스케줄링 하는 방식
Basic block
static code 내에서 연속적인 instruction의 set -> 보통 4~5개의 instruction으로 구성됨
블록 내 특정 instruction이 실행되면 모든 instruction들이 항상 sequential하게 실행되는 특성을 가짐
Basic block의 특성
- basic block은 블록의 맨 마지막 instruction을 제외하고 branch나 jump 를 포함할 수 없다.
- basic block은 블록의 맨 처음 instructio을 제외하고 내 어떠한 instruction도 branch나 jump의 target이 될 수 없다.
Basic block의 한계
size가 너무 작다 -> 추후 local scheduling을 사용할 수 없는 원인이 됨
1. local scheduling -> basic block 내에서 일어남
basic block에 제한된 static instruction scheduling 방식이다.
basic block 내에서 사용 가능한 ILP가 제한되어 있음
for (i = 0 ; i < 100 ; i++)
A[i] = A[i] + B[i];
Loop L.S F0,0(R1) (1)
L.S F1,0(R2) (1)
ADD.S F2,F1,F0 (2)
S.S F2,0(R1) (5)
ADDI R1,R1,#4 (1)
ADDI R2,R2,#4 (1)
SUBI R3,R3,#1 (1)
BNEZ R3,Loop (3)
위 코드는 basic block 내에 있는 코드를 나타낸다.
L.S부터 BNEZ까지 instruction이 sequential하게 실행된다.
이 때 CPI = 15 / 8 = 1.875
하지만 여기서 L.S와 ADD.S 그리고 ADD.S와 S.S 간에 data dependency가 존재한다.
ADD.S -> 2 cycle (1 cycle stall 됨)
S.S -> 5 cycle (1 cycle stall 됨)
BNEZ -> 3 cycle (branch가 taken이라면 3 cycle, not taken이라면 1 cycle)
매번 branch가 always untaken이므로, taken되면 IF와 ID에서 2개의 instruction이 flush되기 때문에 2cycle이 waste되는 문제가 발생한다.
이 문제를 해결하기 위해서는 컴파일 된 코드를 재구성해야 하는데, loop 맨위에 branch를 배치하여 대부분의 경우 branch과 taken되지 않게 하는 것이다.
delay branch
branch prediction이 true건 false건 상관 없이 무조건 뒤따라 오는 instruction을 실행하는 것
delay slot
branch instruction을 일정 갯수의 instruction으로 delay하는 경우, delay된 instruction이 위치하는 공간
컴파일러는 total cycle을 줄이기 위해 basic block 내에서 일부 instruction을 재배치할 수 있다.
위 코드의 순서를 바꾸면 다음과 같다.
Loop L.S F0,0(R1) (1)
L.S F1,0(R2) (1)
SUBI R3,R3,1 (1)
ADD.S F2,F1,F0 (1)
ADDI R1,R1,#4 (1)
ADDI R2,R2,#4 (1)
S.S F2,-4(R1) (3)
BNEZ R3,Loop (3)- SUBI를 L.S 다음으로 위치시킴
- ADDI 2개를 S.S 위로 위치시킴
따라서 컴파일러가instruction 순서를 바꾸어, total cycle이 15 cycle -> 12 cycle로 감소함으로써 낭비되는 cycle을 줄일 수 있다.
이 때 CPI = 12 / 8 = 1.5로 성능이 증가
instruction 재배치 이전과 이후의 execution time을 비교하면 speedup = 15 / 12 = 1.25
local scheduling 방식은 쉽지만 basic block의 size가 매우 작다는 점 때문에 한계가 있다.
따라서 global scheduling 방식의 일부인 loop unrolling방식을 사용해서 data size를 늘리도록 한다.
2. global scheduling -> 여러 basic block 간에 일어남
global scheudling 방식은 basic block에 있는 instruction 갯수보다 더 많은 갯수의 instruction들을 포함하기 때문에 더 효과적이다.
loop는 source code level에서 컴파일러에 의해 최적화 된다.
global scheduling은 cyclic scheduling이라 하는 loop에 중점을 둔다,
cyclic scheduling
1. loop unrolling
2. software pipelining
non-cyclic scheduling
trace scheduling

기존 basic block에 있던 코드를 1번 더 copy하여 loop unrolling을 해주었다. -> 2배로 증가
- offset을 계산하는 부분은 1번으로 충분하기 때문에 중복되는 instruction을 제거해준다.
- WAW, WAR hazard를 제거하기 위해 컴파일러는 FP register를 rename
loop를 unrolling 해주게 되면 한 번의 iteration에서 basic block을 2번 실행할 수 있게 된다.
그렇기 때문에 전체적인 iteration 횟수는 줄어들게 된다.
그리고 다음과 같이 offset이 2배로 증가하는 효과를 확인할 수 있게 된다.
for (i = 0 ; i<100 ; i += 2)
A[i] = A[i] + B[i];
기존 basic block과 대비해 loop unrolling되어 사용된 clock 수는 7clock이다.
따라서 speedup = 15 / 7 = 2.14
superpipeline에서 loop unrolling을 실행하면 17cycle이 걸린다. ( iteration 당 8.5 cycle)
하지만 각 stage마다 또 다른 stage가 추가되어 clock rate가 2배로 빨라졌었다.
따라서 speedup = 2*15/8.5 = 3.52
loop unrolling은 각 iteration이 independent한 경우에 효과적이다.
loop-carried dependency : 연속된 iteration에서 instruction 간 dependency가 발생하게 되는 상황
for (i=5 ; i<100 ; i++)
A[i] = A[i-5] + B[i];
만약 이 loop가 5번 unrolling 된다면
a[0]-a[5]
a[1]-a[4]
a[2]-a[3]
a[3]-a[2]
a[4]-a[1]
a[5]-a[0]
이런 식으로 loop가 중복되므로 RAW dependency가 발생한다.
따라서 ILP가 제한되며, 5번째 loop는 1 번째 loop의 결과를 기다려야 하는 상황이 발생한다.
( 6번째 loop는 2번째 loop의 결과를 기다려야 함... )
Static pipeline의 strengths and weaknesses
장점
- hardware simplicity : 더 복잡한 하드웨어 디자인에서보다 clock rate가 높다.
- very predictable : 간단하므로 예측하기가 쉬움, static하게 성능을 최적화할 수 있다
- dynamic하게 수행되는 프로세서에서보다 energy/power 소모가 적다
단점
- cache miss와 같은 dynamic한 event에 취약하다 -> memory wall problem을 효과적으로 해결하지 못함
- dynamic information이 부족하다 - memory instruction이 코드 내에서 이동할 때 information을 detect하지 못함
- instruction이 thread 순서대로 완료되는 동안 exception을 정확하게 처리하는 것이 어려움
-> 파이프라인이 깊어지고 clock마다 instruction이 많이 issue될 수록 complexity가 증가
'Advanced computer architecture' 카테고리의 다른 글
| register renaming, superscalar (0) | 2024.01.26 |
|---|---|
| Speculative executions (0) | 2024.01.19 |
| Scoreboarding (0) | 2024.01.08 |
| Static pipeline with out-of-order execution completion(1) (1) | 2024.01.05 |
| [Quantitative approach] ch3.4 Overcoming Data Hazards With Dynamic Scheduling (0) | 2023.12.28 |

