
Kim Seon Deok
VLIW(1) 본문
dynamic micro architecture의 한계
클럭 당 더 많은 instruction을 dispatch 하지만 하드웨어 로직이 점점 복잡해 질수록 cost가 증가하고 느려지게 되며 더 많은 power를 소비하게 됨
VLIW : Very Long Instruction Word
소프트웨어는 high-level language로 되어있고 컴파일러에 의해 analyze된다.
컴파일러는 assembly code를 만들고 여기에 optimization technique를 적용한다.
LIW/VLIW에서 instruction processing의 instruction fetch ~ retire까지 모든 단계가 컴파일러에 의해 핸들된다.
하드웨어 complexity와 power를 최소화하며 wide fetch와 dispatch bandwidth를 갖춘 superscalar 아키텍쳐를 가능하게 한다.
VLIW의 idea
매우 간단한 하드웨어를 사용할 수 있다는 점
간단한 하드웨어를 사용하면 높은 frequency로 실행시키게 되며 소비하는 power는 낮아지게 된다.
RAW, WAW, WAR hazard, memory disambiguation, speculation 등 OoO프로세서의 burden, 하드웨어적이었 burden 을 소프트웨어적인 burden으로 옮겨와 해결하고자 하는 것
VLIW아키텍쳐는 각각의 long instruction들이 ops라 하는 여러 MIPS instruction이 그룹으로 묶인 명령어들이 각 slot에 할당되는 것을 말하며 각 slot에 해당되는 stage는 static한 마이크로 아키텍쳐이다.
PC는 long instruction을 가리키고, long instruction의 모든 ops는 한 번에 fetch된다.

다음은 VLIW 의 기본 구조이다.
5개의 slot으로 구성된다.
-1개의 INT/ Branch operation
-2개의 FP operation
-2개의 memory reference opeartion
각각 다른 instruction에 대해 multiple한 slot을 갖는데, 이는 tomasulo algorithm의 backend part와 유사하다.
RISC 아키텍쳐에서 single instruction은 32비트이다 따라서 각 slot은 32비트이며 전체 5개의 slot은 32 * 5 비트이다.
data forwarding이 일어나지 않는다면, 하나의 instruction group은 multiple instruction을 포함하고 fetch - decode - execute 단계를 거친다. 각 instruction은 다른 execution unit으로 dispatch된다.
data forwarding이 발생한다면 발생하는 latency는 다음과 같다.

FP ALU operation의 경우, (fadd -> fadd)이전에 issue된 instruction의 결과를 사용하려면 뒤따르는 instruction은 2 클럭을 기다려야 한다.
OoO 프로세서에서는 뒤따르는 instruction이 실행될 준비가 되어 있지 않으면 stall 되었었다.
LIW 아키텍쳐는 data dependency를 analyze하지 않기 때문에 컴파일러는 2cycle 이후에 instruction을 issue한다.
여기서 LIW 아키텍쳐의 단점을 확인할 수 있다.
컴파일러는 하드웨어의 디테일한 정보를 필요로 하고, 디테일한 정보가 있어야만 instruction optimizing이 가능하다.
Branch delay의 경우, branch taken이라면 target of branch로 jump한다. not taken이라면 very next instruction을 실행한다.
branch delay slot의 latency가 2cycle - 2개의 instruction group이 branch instruction 결과에 상관 없이 flush 되지 않음.
VLIW에 적용된 컴파일러 테크닉
1. Loop Unrolling
loop가 unrolling되면 branch instruction이 제거되고 memory displacement가 조정되며 register rename이 일어난다,
그 다음 VLIW를 optimizing하도록 reorganize된다.
VLIW의 peak performance = clock 당 5개의 instruction 실행
하지만 아래 fifure에서 VLIW는 6클럭을 소비하기 때문에 30개의 instruction을 실행할 수 있다.
VLIW의 효율을 높이기 위해선 더 aggressive 한 컴파일러 최적화 기법으로 loop unrolling을 사용한다,
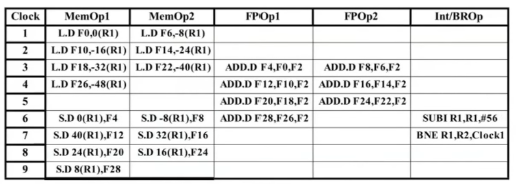
loop가 7번 unroll된 상황으로 7번의 L.D, S.D, ADD.D instruction이 실행된 것을 확인할 수 있다.
loop unrolling의 문제점
- code size : loop 문이 여러 번 복제 되어 code가 크게 확장된다.
- 많은 수의 slot이 낭비되며(NOOP) operation은 register data의 hazard를 피하기 위해 schedule 되어야한다.
- Empty slots : VLIW에서 모든 slot을 가득 채울 수 없다.
- register pressure : architecture reigster의 갯수는 fix되어있다. loop가 unroll되면 컴파일러는 더 많은 레지스터를 사용하게 되고 따라서 register pressure가 증가한다. -> 이를 해결하기 위해 rotating register를 사용
- VLIW로 peak performance에 도달하기 어렵다.
2. Software pipelining
원래 loop의 다른 iteration에서 가져온 instruction들이 pipeline loop의 한 iteration에서 실행되도록 코드를 reconfiguration하는 기법
Loop: L.D F0, 0(R1) O1
ADD.D F4, F0, F2 O2
S.D F4, 0(R1) O3
Loop에 3개의 instruction이 지정되어 있다.
여기서 L.D - ADD.D
ADD.D - S.D에 data dependency가 존재한다.
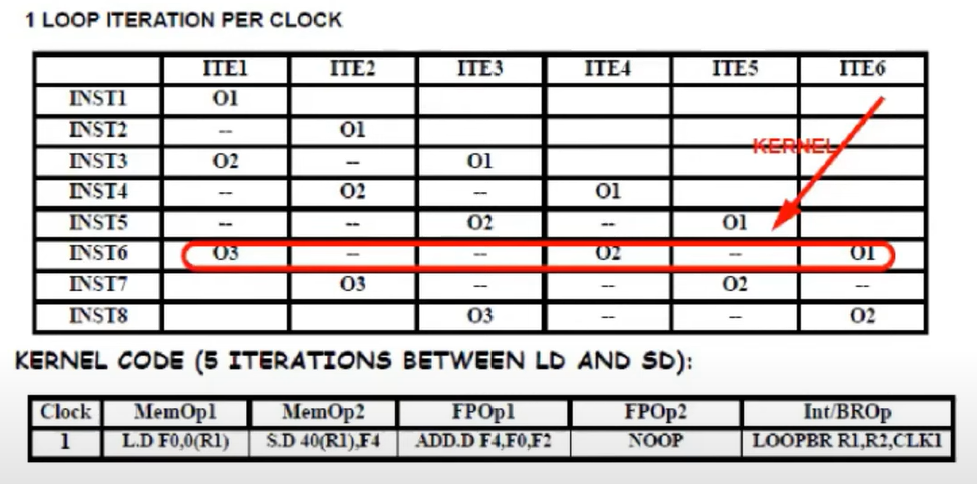
VLIW에서 2개의 memory slot이 있는 한 1 cycle에 2개 이상의 loop iteration을 스케줄링하는 것은 불가능하다.
loop가 반복적으로 실행되기 때문에 다른 iteration은 1클럭에 할당 될 수 있다.
INST6에서 모든 instruction(O1, O2, O3)이 실행되고 있는 것을 확인할 수 있다.
따라서 이 부분을 kernel로 사용한다. kernel 코드는 kernel의 각 operation을 VLIW 명령어의 하나의 slot에 배치하여 얻어진다.
[iteration 1]
F0는 L.D에 의해 produce됨
F0는 ADD.D에 의해 consume 됨
F0 값은 O2 전까지 maintain 됨
F0의 lifetime = INST1~INST3
이후 F0에는 새로운 값이 할당된다.
F4는 ADD.D에 의해 produce됨
F4는 S.D에 의해 consume 됨
F2값은 O3 전까지 maintain됨
F2의 lifetime = INST3~INST6
[iteration 2]
O1은 F0을 사용할 수 없음
(F0는 iteration 1의 O1에 의해 produce 되고 이 값을 O2가 consume하기까지 maintain해야 하기 때문에)
따라서 iteration2의 O1값을 새로운 register에 할당해야 한다.
architecture register는 fix된 갯수만큼 한정되어 있기 때문에 available한 reigster를 찾기가 어렵다.
이 부분에서 loop unrolling의 문제점이 발견된다.
Loop: L.D F0, 0(R1) O1
ADD.D F4, F0, F2 O2
MUL.D F6, F0, F4 O3
S.D F4, 0(R1) O4
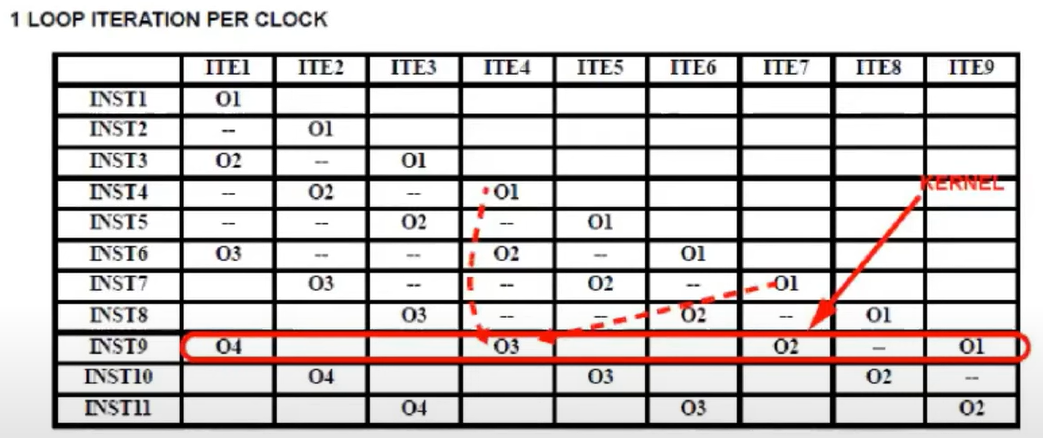
iteration4에서 O3는 iteration4의 O1의 값을 read하게 된다.
하지만 F0에서 WAR hazard가 발생함으로 인해 iteration7에서 O1의 값이 forwarding 된다.
data dependency 존재
L.D - ADD.D -> F0
ADD.D - MUL.D -> F4
L.D - MUL.D -> F0
F0는 O1에 의해 produce되고 O2, O3에 의해 consume되기 때문에 O3까지 maintain됨
F4는 O2에 의해 prouce되고 O3에 의해 consume되므로 O3까지 maintain된다.
Iteration7의 O1은 data를 O1에 write하려 함
L.D와 ADD.D 간 WAR 해저드로 인해 Iter 7의 O1 값이 O3 값으로 forward 된다.
이러한 경우를 피하기 위해 컴파일러는 register의 life time을 analyze해야 한다.
일반적으로 register 값은 서로 다른 클럭에서 스케줄 가능한 2개의 다른 operation의 source reigster 값이 될 수 있다.
이 경우 2 operation은 최악의 경우에 발생하는 latency에 대한 스케줄링이 필요하다.
WAR 해저드를 피하기 위해 register renaming이 필요하다.
Solving WAR hazards with rotating registers
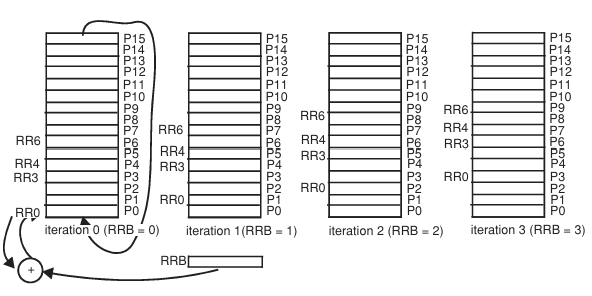
위에서의 WAR 해저드 문제를 해결하기 위한 솔루션으로 rotating register를 이용한다.
RR0는 마지막 instruction인 P0에 할당된다. 그리고 이 값을 계속 유지한다.
OoO 프로세서에서 register renaimng은 하드웨어에 의해 자동으로 실행되었지만, VLIW에서는 register renaming을 하지 않는다. 따라서 컴파일러는 register number를 rotating할 때 architecture register lifetime에 근거해서 할당해야 한다.
각 iteration에서 rotation regsiter rri는 다른 physical register Pj에 매핑된다.
rotating register에서 physical register number로의 mapping은 rotating register base register(RRB register)의 값에 의해 컨트롤된다. loop를 제어하는 branch가 실행될 때마다 rotation register base reigster는 1씩 증가한다.
RR number는 RR base register module로 register file의 크기만큼 추가되기 때문에 ISA에서 액세스 되는 rotation register에 대한 physical register 할당을 rotation시킨다.
iteration1에서 O1에 할당되는 레지스터 → rr1
iteration1에서 O2에 할당되는 레지스터 → rr2
iteration1에서 O3에 할당되는 레지스터 → rr3
rr1의 life time 이 지나면 rr1,rr2를 다른 physical register에 할당
VLIW - Slot conflicts
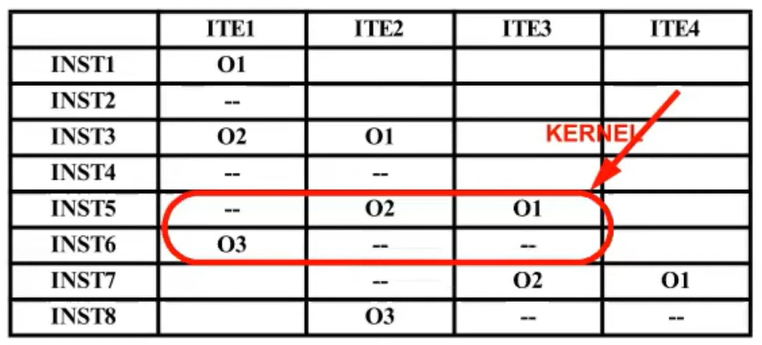
새로운 VLIW 하드웨어를 사용한다면 이 VLIW 하드웨어는 이전 VLIW 보다 적은 수의 slot이 할당되어 있을 것이다
-> 1LD/ST, 1FP, 1INT/BR로 총 3개의 slot
slot 수가 부족하기 때문에 1clock 안에 모든 instruction을 다 다음을 수 없다.
그렇기 때문에 2clock에 걸친 kernel이 만들어지게 된다.
따라서 위와 같은 경우, kernel을 위한 software pipelining이 필요하고 VLIW hardware configuration에 근거해서 kernel의 configuration이 바뀌게 된다.
'Advanced computer architecture' 카테고리의 다른 글
| VLIW(2) & Vector Processor (0) | 2024.02.08 |
|---|---|
| register renaming, superscalar (0) | 2024.01.26 |
| Speculative executions (0) | 2024.01.19 |
| Static pipeline with out-of-order execution completion(2) (0) | 2024.01.11 |
| Scoreboarding (0) | 2024.01.08 |


