
Kim Seon Deok
7. Numpy & NLTK 본문
Numpy
수학 및 과학 연산을 위한 python 패키지
Numeric + Python
주로 행렬 연산과 수치 해석을 위해 사용
Python 패키지이지만 내부적으로 C로 구현되어 속도가 빠르다 >> Numpy가 Python보다 빠르다
NLTK
자연어처리(Natural Language Processing, NLP)
인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 모사할 수 있도록 연구하고 이를 구현하는 인공지능의 주요분야 중 하나.
전통적인 NLP분석 방법을 제공해주는 도구 모음 패키지
주로 텍스트 데이터의 전처리 과정에서 사용
NLTK를 위한 Data pre - processing(데이터 전처리)
1.Tokenize
2.Stemming
3.Stopwords
Tokenize
문장을 token으로 잘라주는과정
Token : 어휘분석(lexical analysis)의 단위
주로 단어가 Token의 단위로 사용됨
Tokenizer : Tokenize 해주는 객체

Stemming
형태소 분석
단어의 핵심 뜻 부분만을 추출하는 과정

Stopwords
많이 쓰이지만 분석에는 큰 도움이 안되는 단어. 그러한 단어를 없애는 과정

Document similarity
One - hot encoding(단어 기준)
단어를 컴퓨터가 이해할 수 있도록 단어를 0과 1로 표현하는방법
단어 개수만큼 0을 채움
해당 단어 위치만 1로 바꿔줌

One - hot encoding(문장 기준)
단어를 컴퓨터가 이해할 수 있도록 문장을 0과 1로 표현하는 방법
모든 문장에 있는 단어를 모아 0으로 채움
특정 문장에 있는 단어만 1로 바꿔줌

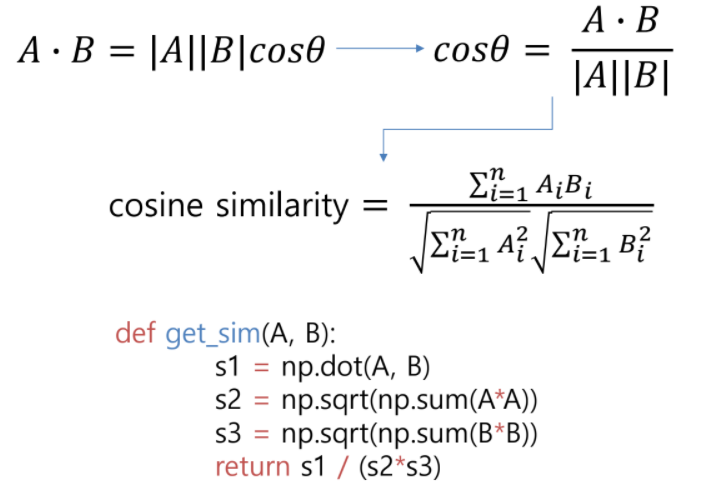
Cosine similarity
문장을 vector로 표현했을 때 두 vector 사이의 사잇각을 이용해 두 문장의 유사도를 구하는 방법


'AI > Deep Learning' 카테고리의 다른 글
| 밑바닥부터 시작하는 딥러닝 1 - 3장 : 신경망 (0) | 2022.03.08 |
|---|---|
| 밑바닥부터 시작하는 딥러닝1 - 2장 : 퍼셉트론 (0) | 2022.03.08 |
| 6. Batch Normalization (0) | 2022.01.21 |
| 5. CNN을 활용한 대표적 모델 (0) | 2022.01.21 |
| 4. CNN 기초 (0) | 2022.01.21 |



