
Kim Seon Deok
3. 딥러닝 학습 방법론 본문
데이터셋 구성

Training set
실제 학습에 사용되는 데이터(전체의 80%)
Validation set
학습 중간 중간에 사용되는 평가 데이터 (전체의 약 10%)
best performance model을 선택하는 데 사용됨
Test set
학습 과정에서는 절대 사용하지 않는 데이터 (전체의 약 10%)
내 모델이 실제 사용되는 상황에서 마주하는 데이터 >> 최종성능을 판단
validation set과 함께 사용하지 않는다!!
Weight Initialization
딥러닝 학습의 목표 : 좋은 weight의 값을 찾는 것
시작이 어떠한값이어도 좋은 weight에 도달할 수 있을까? >> NO
시작 값이 좋아야 학습도 잘된다.
특정 분포를 정해두고 해당 분포에서 sampling 한 값들을 weight의 초깃값으로 설정
좋은 분포를 설정하는 것이 좋은 시작값을 갖는 것 > 정규 분포를 이용 (평균은 0 , 표준편차의 값을 변경)
sampling 을 하기 때문에 기본적으로 딥러닝학습에는 random성이 존재
같은 상황(모델구조, 데이터, 하이퍼 파라미터)에서도 다른 결과가 나오게 된다.
1.Xaiver Initialize
표준편차가 1/√n인 저육분포로 초기화 (n : 앞층 노드 수)
activation function이 sigmoid일 때 사용
n = √(2/n_in+n_out)으로 표현하기도 한다.

2.He Initialize
표준편차가 √(2/n)인 정규분포로 초기화
activation function이 ReLU일 때 사용

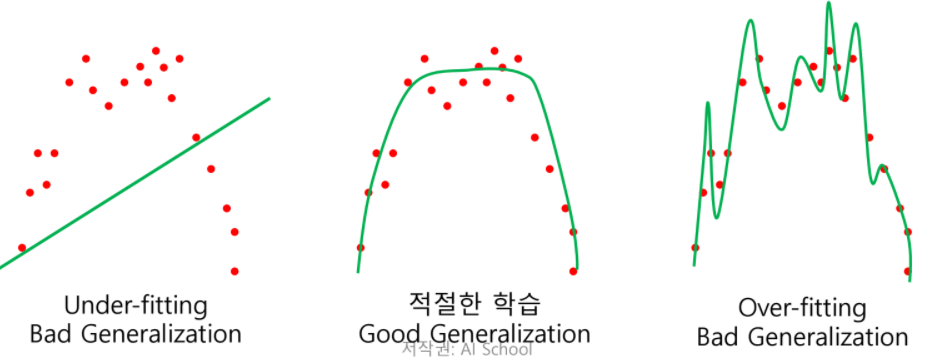
Overfitting
딥러닝모델이 겪는 일반적이지만 중요한 문제점
모델이 학습(Train)데이터에 지나치게 집중하면서 실제로 테스트(Test)데이터에서 결과가 더 안좋게 나오는 현상
학습데이터로 학습하고 테스트 데이터에서 성능이 좋은 것을 Generalize(일반화)가 잘 되었다고 얘기 한다.
Overfitting의 극복방법
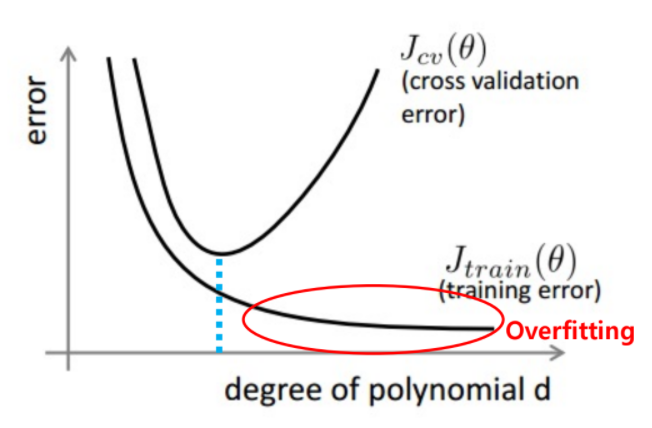
1.Early Stopping
Trainloss & Eval graph 상에서 최적 포인트를 자동으로 찾아 지정한 epoch까지 모두 학습하는 게 아니라 최적 포인트에서 학습과정을 미리 멈추는 기법
학습은 하되, 매 시점마다 accuracy 측정(accuracy 가장 높고 error가 가장 낮은 값)
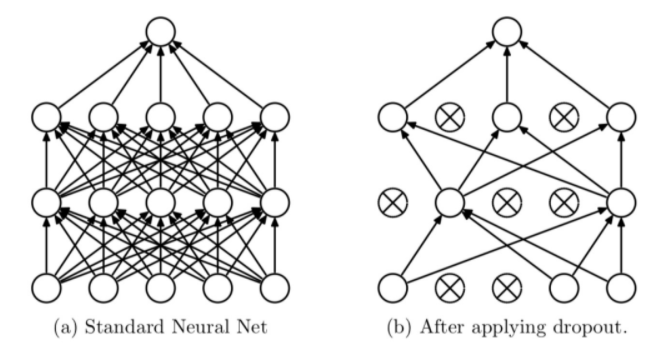
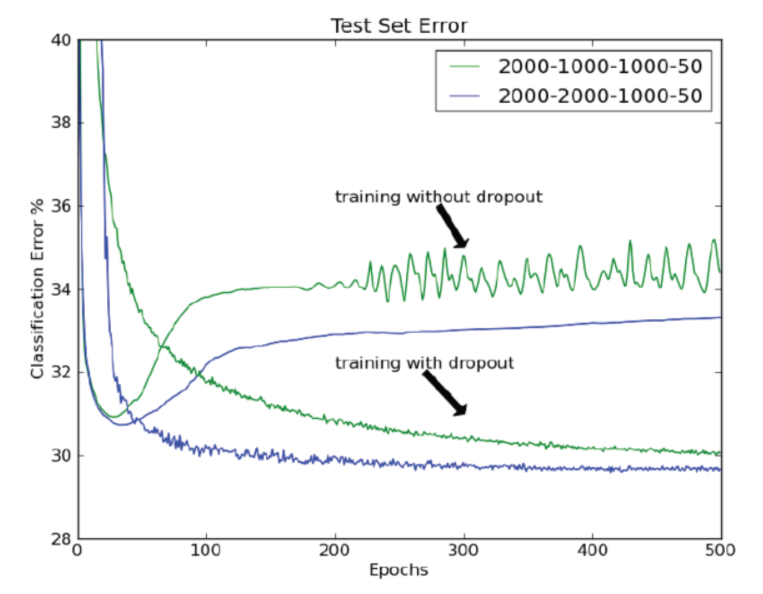
2.Dropout
네트워크의 일부를 생략하는 것
학습 중 Forward 과정에서 일부 perceptron을 특정 확률(p)사용 / 미사용함.
p값은 hyper parameter이며 일반적으로 0.5를 사용함(p값이 작아지면 원본과 비슷해짐)
평가과정에서는 Dropout을 사용하지 않고 모든 perceptron을 사용
정해진 데이터셋으로 한 번 학습 하는 과정으로 동일한 네트워크를 이용해 여러 네트워크를 만들어 이용한 최적 네트워크 탐색과정의 효과를 얻을 수 있음
연산 시간이 줄어듦
3.Weight decay, Weight restriction(parameter Norm Penalties)
Overfitting된 weight들은 보통 그 크기가 매우 크다.
따라서 그 weight들의 값을 너무 키우지 않는 방법으로 Overfitting을 방지한다.
-Weight decay(가중치 감소) E = error
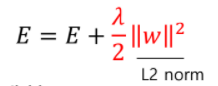
-Weight restriction(가중치 제한)
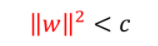
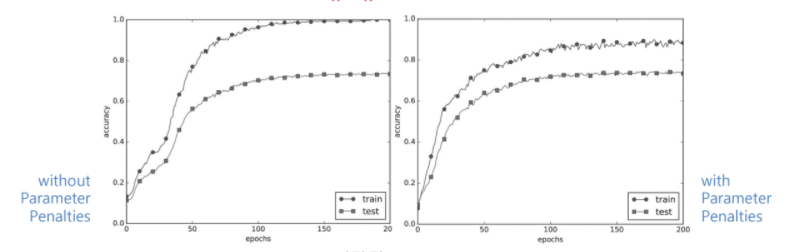
4.Data Augmentation
데이터가 늘어나는 효과
데이터의 특징학습에 도움
'AI > Deep Learning' 카테고리의 다른 글
| 5. CNN을 활용한 대표적 모델 (0) | 2022.01.21 |
|---|---|
| 4. CNN 기초 (0) | 2022.01.21 |
| 1. Back propagation (0) | 2022.01.21 |
| 딥러닝 학습방법론 (0) | 2021.11.23 |
| 딥러닝 기초이론 학습의 과정-2 : Loss and Gradient (0) | 2021.11.23 |



