
Kim Seon Deok
[General Purpose GPU] ch3.2 TWO - LOOP APPROXIMATION ~ ch3.3 THREE-LOOP APPROXIM 본문
[General Purpose GPU] ch3.2 TWO - LOOP APPROXIMATION ~ ch3.3 THREE-LOOP APPROXIM
seondeok 2024. 1. 7. 03:28
*General - Purpose Graphics Processor Architecture의 chapter 3.2 TWO - LOOP APPROXIMATION ~ 3.3 THREE-LOOP APPROXIMATION 를 읽고 정리한 내용입니다.

앞서 one loop approximation은 single scheduler를 다루었다.
GPU에서 latency를 hiding하려면 현재 실행되고 있는 instruction이 끝나지 않은 상황에서 다음 instruction을 issue할 수 있어야 한다. 하지만 one loop approximation은 scheduling logic이 thread identifier와 다음 instruction address에만 access할 수 있기 때문에 latency hiding을 하기에 효율적이지 못하다. 뿐만 아니라 issue하려는 instruction이 아직 완료되지 않은 instruction에 dependent한지 아닌지도 알 수 없다.
dependency에 대한 정보(data hazard, structure hazard)를 알기 위해선 memory에서 instruction을 fetch해와야 한다.
이를 위해 GPU는 instruction cache에서 fetch된 instruction을 저장하는 instruction buffer를 만들었다.
scheduler는 이 instruction buffer에 있는 어떤 instruction이 pipeline에 issue될 지를 결정한다.
instruction memory(fetch)는 first-level cache이다. instruction cache로부터 cache hit 혹은 cache miss로 인한 instruction에 대한 정보를 instruction buffer에 저장함으로써 instruction buffer는 instruction miss-status holding register(MSHRs)와 함께 instruction cache misss latency를 hiding하는 것을 돕는다.
가장 간단하게 instruction buffer는 warp 당 하나 이상의 instruction에 대한 storage를 가지도록 구성할 수 있다.
기존 CPU에서 instruction 간 dependency를 detect하기 위해 사용했던 방법
1. reservation station : name dependency를 제거하기 위해 사용되었지만 추가적인 logic을 사용해야 하기 때문에 area와 energy 측면에서 cost 발생
2. scoreboard (CDC6600): in-order execution(이 경우 scoreboard는 매우 간단한 구조)과 out-of-order execution(이 경우 scoreboard는 매우 복잡한 구조)을 모두 지원
각 register는 scoreboard에 single bit로 표현되는데 해당 resgister에 write를 수행하는 instruction이 issue되면 1로 세팅된다. scoreboard에 bit가 1로 설정된 register를 read하거나 write하려는 instruction은 해당 bit가 write를 수행하는 instruction에 의해 bit가 clear될 때까지 stall된다. -> RAW hazard, WAW hazard 방지
in-order scoreboard
장점)
- register file에서의 read가 in-order로 제한되면 register read가 순서대로 이루어짐, WAR hazard 방지
- area와 energy 소비가 적음
단점)
- multiple warp를 사용하는 경우 warp 각각이 독립적으로 실행되기 때문에, warp 간의 dependency와 interaction을 관리해야 한다.
- scoreboard를 구현하려면 register가 필요한데, GPU에는 많은 수의 register들이 포함되어 있음(core 당 64개의 warp가 할당되어 있고 1개의 warp 당 128개 register 할당되어 있음 -> core 당 2^13만큼 register 할당)
- dependency를 맞닥뜨리는 instruction은 해당 dependency를 가진 이전 instruction이 register file에 결과를 write할 때 까지 scoreboard에서 operand를 반복해서 lookup해야 한다.
single thread design에서 in-order scoreboarding을 구현하기에는 복잡하다.
in-order multi-thread processor에서는 여러 thread의 instruction가 이전 instruction이 끝날 때까지 기다려야 한다.
이럴 경우 register에 추가적인 read port가 필요하다. 이에 대한 대안책으로 매 cycle 마다 scoreboard를 확인하는 warp의 갯수를 제한하는 방법도 있지만 이것은 scheduling에 필요한 warp의 갯수를 제한한다.
scoreboarding에서는 특정 instruction들이 dependency가 모두 있는 상황이라면, 다른 dependency가 없는 instruction이 issue되지 않을 수도 있다.
따라서 위의 2가지 단점을 해결하기 위해, warp에 할당된 register 당 single bit을 유지하면서, 적은 수의 entry(issue되었지만 execution이 완료되지 않은 instruction을 포함)를 포함하는 새로운 형태의 register를 설계했다. (Coon et al.’s scoreboard)
기존 in-order scoreboard는 instruction이 issue될 때 그리고 write back될 때 access된다.
방금 말한 새로운 형태의 scoreboard는 instruction buffer로 instruction이 저장될 때 그리고 instruction이 결과값을 register file에 write할 때 access 된다.
instruction이 instruction cache로부터 fetch되어서 instruction buffer에 저장되면, warp에 할당된 scoreboard entry는 instruction의 source register와 destination register를 compare한다.
-> scoreboard 내 각 entry에 short bit vector를 생성하고 각 entry가 특정 instruction의 operand와 일치하는 경우 set
-> short bit vector는 instruction buffer 내에서 instruction과 함께 copy되어 다음 instruction의 실행에 사용됨
instruction buffer 내 dependency bit은 instruction이 결과값을 register file에 write back함에 따라 해제된다.
모든 entry가 사용되면 fetch가 stall 되거나 instruction이 discard되어 다시 fetch해와야 한다.
instruction의 execution이 완료되어 register file에 write하게 되면 scoreboard의 entry를 free하고 instruction buffer에 저장된 동일한 warp의 다른 instruction에 대한 dependency bit도 해제한다.
Two - loop approximation
첫 번째 loop : instruction buffer에 공간이 있는 warp를 선택하고 해당 warp의 PC를 lookup하며 instruction cache에 access하여 다음 instruction을 fetch해옴
두 번째 loop : 아직 처리되지 않은 dependency가 없는 instruction을 선택하고 이를 execution unit으로 issue
Three - loop approximation
long memory latency를 hide하기 위해서는 core 당 많은 수의 warp를 support할 수 있어야 하고 cycle 마다 warp 간 swicthing을 support할 수 있어야 한다. 그러기 위해선 large register file이 필요하다.
SRAM memory의 면적은 port 갯수에 비례한다.
register file은 instruction이 issue될 때 마다 operand 당 1개의 port를 필요로 한다.
register file의 area를 줄이기 위해서는 single-port memory에 multiple bank를 사용함으로써 port 갯수를 늘리는 것이다.
이러한 방식을 operand collector라 하고 instruction set architecture에 이러한 bank를 노출시켜 register file에 대한 access 및 효율성을 높인다.
register file은 4개의 single-port logical bank로 구성된다.
register file은 매우 크고 각 logical bank는 physical bank로 구성된다.
logical bank는 crossbar를 거쳐서 staging register(=pipeline register)로 연결된다. buffer source operand는 staging register 를 통과하고 SIMD execution unit으로 간다.
Arbitrator는 각 bank의 access를 control하고 crossbar를 거쳐 알맞는 staging register로 결과값을 보낸다.
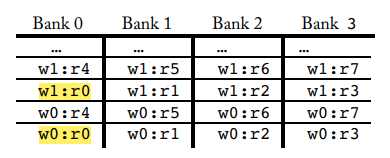
computation에 필요한 register 갯수가 logical bank 갯수보다 많으면 warp는 각 bank에 round 방식으로 할당된다.
Bank 0 ~ Bank 3 에 warp 0의 register 0 ~ register 3 까지 순차적으로 할당
warp 0의 register 4 ~ register 7 까지 순차적으로 할당
warp 1의 register 0 ~ register 3 까지 순차적으로 할당
warp 1의 register 4 ~ register 7 까지 순차적으로 할당
결과적으로 각 warp 마다 r0는 같은 bank에 할당된다 (warp 0 의 r0과 warp 1 의 r0은 모두 bank 0 에 할당됨)

첫 번째 multi-add 연산인 instruction i1은 bank 1, 0, 2에 있는 레지스터 r5, r4, r6으로부터 read하고
두 번째 add 연산인 instruction i2는 bank1에 있는 레지스터 r5, r1으로부터 read한다.
cycle 0 -> warp3은 instruction i1을 issue
cycle 1 -> warp 0은 instruction i2를 issue
cycle 4 -> warp 1은 bank conflict로 인해 instruction i2를 issue
cycle 1 -> warp3으로부터 instructuion i1은 3개의 source register를 read할 수 있음
cycle 2 -> warp0으로부터 instruction i2는 2개의 source register 중 1개만 read할 수 있음 (나머지 한개도 bank1에 매핑되어 있기 때)
cycle 3 -> warp3의 i1이 write back함에 따라 warp1은 나머지 source register를 read
cycle 4 -> warp1로부터 instruction i2는 첫 번째 source operand만 read 할 수 있음 (나머지 한개도 bank1에 매핑되어 있기 때)
cycle 5 -> warp0로부터 instruction i2는 두 번째 source operand read
cycle 6 -> warp1로부터 instruction i2는 두 번째 source operand read
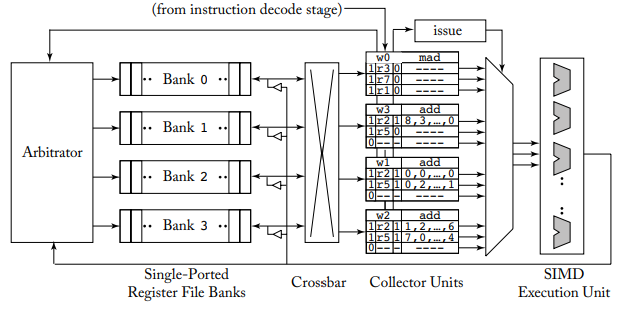
위는 operand collector이다.
이전의 register file과 비교했을 때 staging register가 collector unit으로 replace되었다.
instruction이 register read stage에 들어갈 때 각 instruction은 collector unit에 할당된다.
collector unit이 다수 있게 되면 source operand를 read하는 작업을 overlap할 수 있기 때문에 instruction 간 bank conflict를 줄일 수 있다.
각 operand collector unit은 instruction을 실행하기 위해 필요한 source operand를 저장하는 목적의 buffering space를 갖고 있다. multiple instruction을 실행하기 위해 source operand가 늘어나게 되면 multiple register file bank를 parallel하게 access할 수 있게 되면서 arbitrator는 더 높은 bank-level parallelisim을 달성할 수 있다.
operand collector는 bank conflict를 막기 위해 scheduling 방식을 사용한다.
이 때 이전 register file에서의 layout과 register layout 방식이 달라진다.
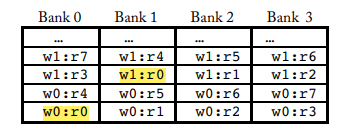
Bank 0 ~ Bank 3 에 warp 0의 register 0 ~ register 3 까지 순차적으로 할당
warp 0의 register 4 ~ register 7 까지 순차적으로 할당
warp 1의 register 3, register 0, register 1, register 2 순으로 할당
warp 1의 register 7, register 4, register 5, register 6 순으로 할당
결과적으로 각 warp 마다 r0는 다른 bank에 할당된다 (warp 0 의 r0는 bank 0, warp 1 의 r0은 bank 1 에 할당됨)
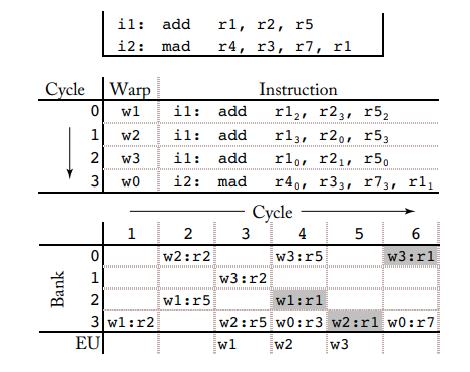
cycle 0 ~ cycle 2 : warp1, warp2, warp3으로 부터 instruction i1 issue됨
cycle 3 : warp0으로 부터 instruction 2 issue 됨
i1의 add r1 r2 r5에서 r1과 r5는 같은 bank에 할당되어 있다.
warp가 다르면 다른 bank에 액세스해서 warp 간 write bank 단계에서 발생하는 conflict를 줄이고 다른 warp로부터 source operand를 읽어올 수 있다.
cycle 1 -> warp1로부터 Bank3에 있는 r2를 read
cycle 4 -> Bank2에 있는 warp1의 r1에 write back함 + Bank0 warp3의 r5를 read + Bank3 warp0의 r1을 read -> 모두 동시에 일어남
여기서 다른 instruction이 issue되는 것에서 순서가 없기 때문에 WAR hazard가 발생할 수 있다.
-> 동일한 warp 내에서 두 개의 instruction이 operand collect에 존재하고 첫 번째 instruction은 register를 read하고 두 번째 instruction은 register를 write -> 첫 번째 instruction의 operand가 반복되는 bank conflict에 마주치고 두 번째 instruction은 첫 번째 instruction이 오래된 값을 read하기 전에 값을 write 해버림
WAR hazard의 발생을 막으려면 동일한 warp로부터 instruction은 operand collector를 지나 execution unit으로 프로그램된 순서에 따라 실행되도록 하는 것이다.
low hardware complexity와 성능을 측정하기 위한 방법
1. release-on-commit warpboard
warp 당 최대 1개의 instruction만 execute되도록 함
-> 성능이 오히려 감소
2. release-on-read warpboard
warp 당 1개의 instruction만 execute됟록 operand collector에서 operand를 collecting
-> 최대 10% workload가 slowdown
3. bloomboard
작은 bloom filter를 사용해 register read를 track
-> WAR hazard 발생
나중에 Maxwell GPU는 read dependency barrier를 도입해 특정 control instruction을 manage하도록 하여 WAR hazard의 발생을 막았다.
register read stage는 operand collector unit을 다 써버릴 것이다. 이는 memory system과 연관이 있다.
warp에서 실행되는 single memory instruction은 multiple separate operation으로 분리된다. 분리된 각 operation은 주어진 cycle 동안 pipeline을 fully utilize한다.
일반적으로 single thread CPU 파이프라인에서 structural hazard가 발생하면 더 이전에 실행되었었던 instruction을 stall 시켰었다. 하지만 이 방법은 multi-thread throughput 아키텍쳐에서는 바람직 하지 않다.그 이유는 다음과 같다.
[ multi-thread throughput 아키텍쳐에서 structural hazard 발생 시 instruction을 stall하는 것이 바람직하지 않은 이유 ]
1. register file의 크기가 크고, 전체 graphics 파이프라인을 support하기 위해 필요한 pipeline stage 수가 많은 경우, stall signal을 distribute하는 것이 critical path에 영향을 줄 수 있기 때
2. 특정 warp의 instruction을 stall하면, 다른 warp의 instruction이 이후에 stall될 수 있다.
여기서, 다른 warp의 instruction이 stall을 일으켰던 instruction이 필요로 했던 resource를 필요로 하지 않는다면, throughput이 낮아질 수 있다.
이러한 문제를 해결하기 위해 instructoin replay를 사용한다.
instruction replay는 variable latency가 있는 이전 instruction에 dependent한 instruction을 예측적으로 scheduling할 때 사용하는 복구 매커니즘이다.
load instruction은 L1 cache에서 hit 혹은 miss를 일으킬 수 있지만, high frequency를 사용하는 CPU design에서는 L1 cache access를 최대 4clock cycle동안 pipeline화 할 수 있다.
일부 CPU에서는 load instruction에 따라 instruction을 예측적으로 wake up 하여 single thread performance를 향상시킨다.
그러나 GPU에서는 energy를 낭비하고 throughput을 감소시키는 경항이 있기 때문에 speculation을 가급적 사용하지 않는다.
대신 instruction replay은 pipeline을 막고 stall로 인해 발생하는 circuit area와 timing overhead를 막기 위해 사용된다.
instruction replay 를 구현하기 위해서 GPU는 instruction을 instruction buffer에 보관하며 instruction의 개별적인 부분의 실행이 완료될 때까지 기다릴 수 있다.
'General Purpose GPU' 카테고리의 다른 글
| [General Purpose GPU] ch3.4 Research directions on branch divergence(1) (0) | 2024.01.15 |
|---|---|
| [General Purpose GPU] ch3.1 ONE - LOOP APPROXIMATION (0) | 2024.01.02 |
| [General Purpose GPU] ch2. Programming model (0) | 2023.12.28 |
| [General Purpose GPU] ch1. Introduction (1) | 2023.12.27 |
