
Kim Seon Deok
[CUDA] ch2. CUDA Memory Management - Global memory 본문
CPU 와 GPU architecture는 기본적으로 다르다. 그렇기 때문에 각 architecture에서 memory hierarchy 역시 각각의 size와 type에 대해서도 다르고, 목적과 design 측면에서도 다르다.
적절한 memory hierarchy를 최적으로 사용했을 때 CUDA kernel을 launching하게 되면 최대 성능을 얻을 수 있다.
따라서 알맞은 memory type을 고르는 것이 중요하다.
GPU application performance constraints

GPU application의 performance에 영향을 주는 요인들 중 memory와 관련된 제약 사항이 가장 큰 부분을 차지하고 있다. 대부분의 시간 동안 application의 성능은 memory와 관련된 제약으로 인해 bottleneck이 일어나게 되므로, 알맞은 type의memory를 효율적으로 사용하는 것이 중요하다.
GPU는 latency hiding architecture로, 많은 수의 thread들을 execution에 사용해서 long memory access latency를 tolerate한다. 또한 memory에 대한 surplus call들은 일부 thread가 stall하거나 waiting 하는 것을 막고, 일부 SM들이 idle한 상태에 있는 것을 막는다. CUDA architecture는 이러한 memory bottleneck문제를 다루기 위해 여러 다른 memory access 방법을 사용한다.
CPU memory에서 출발해 GPU memory를 거쳐 GPU의 SM core에 도달할 때까지 data element가 computation을 위해 통과하는 path는 다음과 같다.
memory bandwidth는 각기 다르며, access latency 또한 각각 다르다.
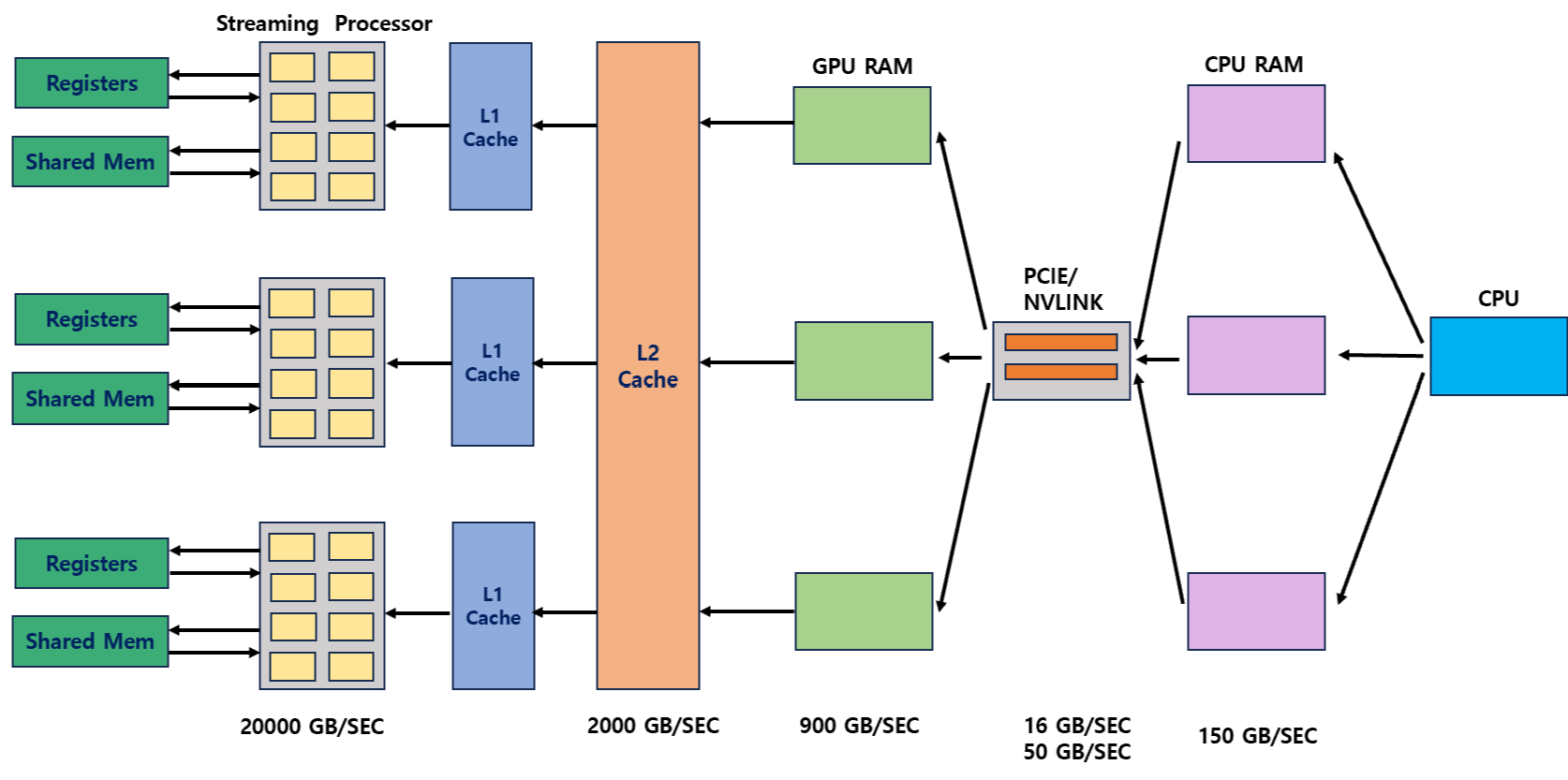
data path는 CPU로 시작해서 register에 도달하고 최종 computation은 ALU/cores에서 일어난다.
GPU의 Memory hierarchy

각 memory의 size, latency, throughput, visibility는 모두 다르다.
- Global memory = Device memory
- Shared memory
- Read - only data / cache
- Pinned memory
- Unified memory
GPU의 Memory hierarchy에 있는 memory는 다양하므로, 이 memory들을 적절하게 최적화하는 방법이 중요하다.
<optimization의 단계>
1. Analyze
2. Parallelize
3. Optimize
Global memory = Device memory
- global memory는 cudaMemcpy를 통해 CPU의 memory에서 전송된 모든 memory의 기본 staging area이다
- global memory의 kernel은 모든 thread에게 visible하며 CPU에게도 visible하다.
- __device__로 data를 선언하고 cudaMalloc으로 할당한다.
- cudaMalloc - cudaFree API를 사용해 명시적으로 memory allocation 및 free를 관리한다
Coalesced VS Uncoalesced global memory access
[ CUDA Block이 SM에 할당되는 과정 -> warp 이용]
warp
- SM의 thread scheduling / execution 의 기본 단위이다.
- NVIDIA -> warp라고 하며 AMD에서는 wavefront라 한다.
- warp는 32개의 thread로 구성되고 wavefront는 64개의 thread로 구성된다.
- block이 SM에 할당되면, 해당 block은 warp라 하는 32개의 thread unit으로 나누어 진다.
- warp는 CUDA의 기본 실행 단위이다.
- ex) 2개의 block이 1개의 SM에 할당되고 각 block에는 128개의 threads가 존재한다고 하면,
- -> block 내 warp 수 = 128 / 32 = 4 warps
- -> SM 내 총 warp 수 = 4 * 2 = 8 warps
[CUDA Block이 warp로 divide되고 나서 GPU SM으로 schedule되는 과정]
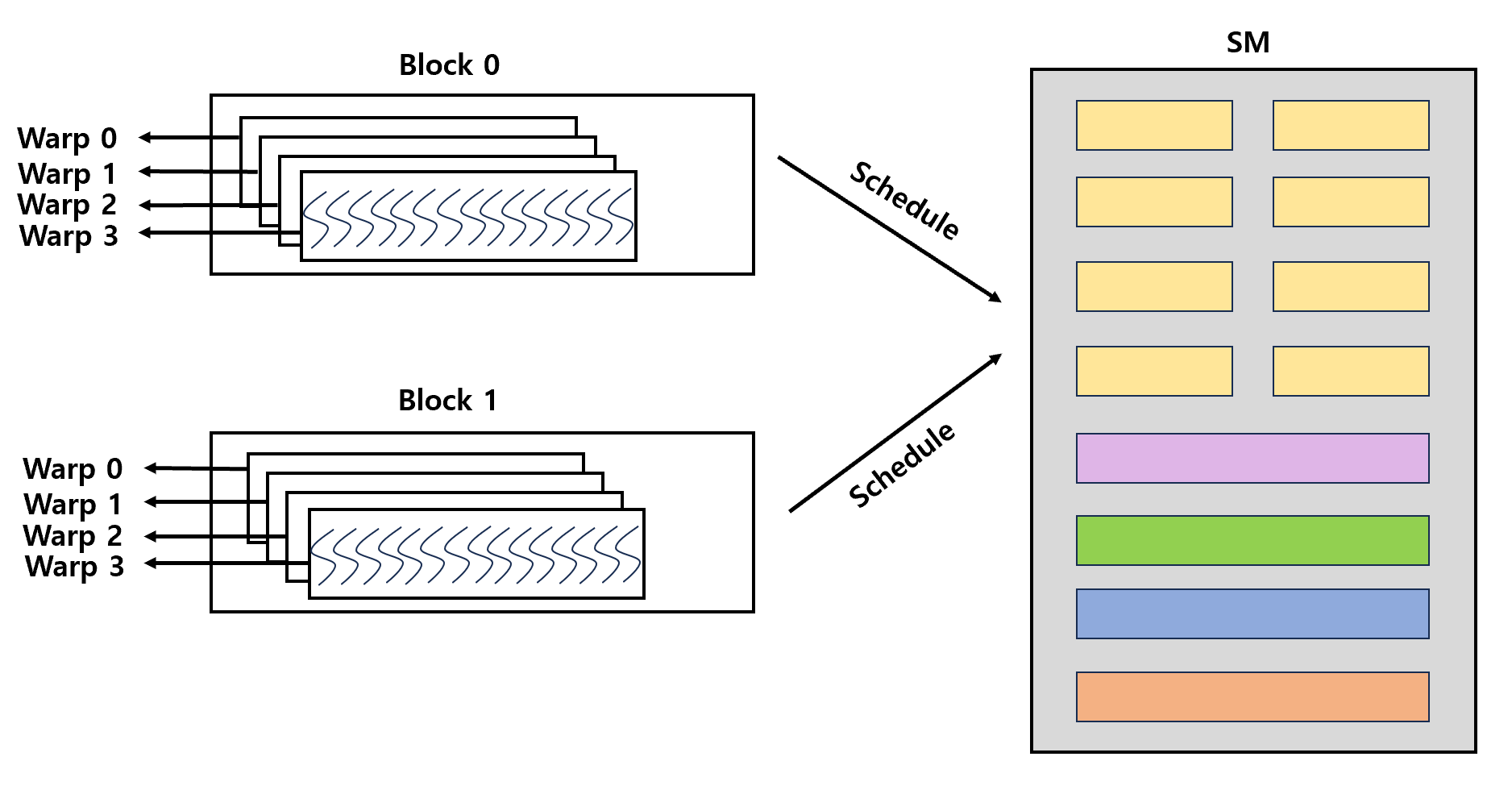
Block과 warp가 SM 및 core에서 schedule되는 방식은 GPU 세대에 따라 구조적으로 다를 수 있다.
available한 warp들 중 다음 instruction을 위한 operad를 갖춘 warp들이 scheduling 된다.
CUDA는 SIMT 모델을 따르기 때문에, scheduling 되는 모든 warp에 존재하는 thread들은 하나의 동일한 instruction을 동시에 가져오고 실행한다.
SM에 warp가 할당되고 실행되고 나서 실행되어, global memory로 access될 때, memory를 최적으로 활용하려면 access가 coalesced해야 한다.
- Coalesced global memory access -> SM에 속한 여러 thread에서 global memory로의 Sequential memory access가 인접하다
- Uncoalesced global memory access -> SM에 속한 여러 thread에서 global memory로의 Sequential memory access 가 인접하지 않다.
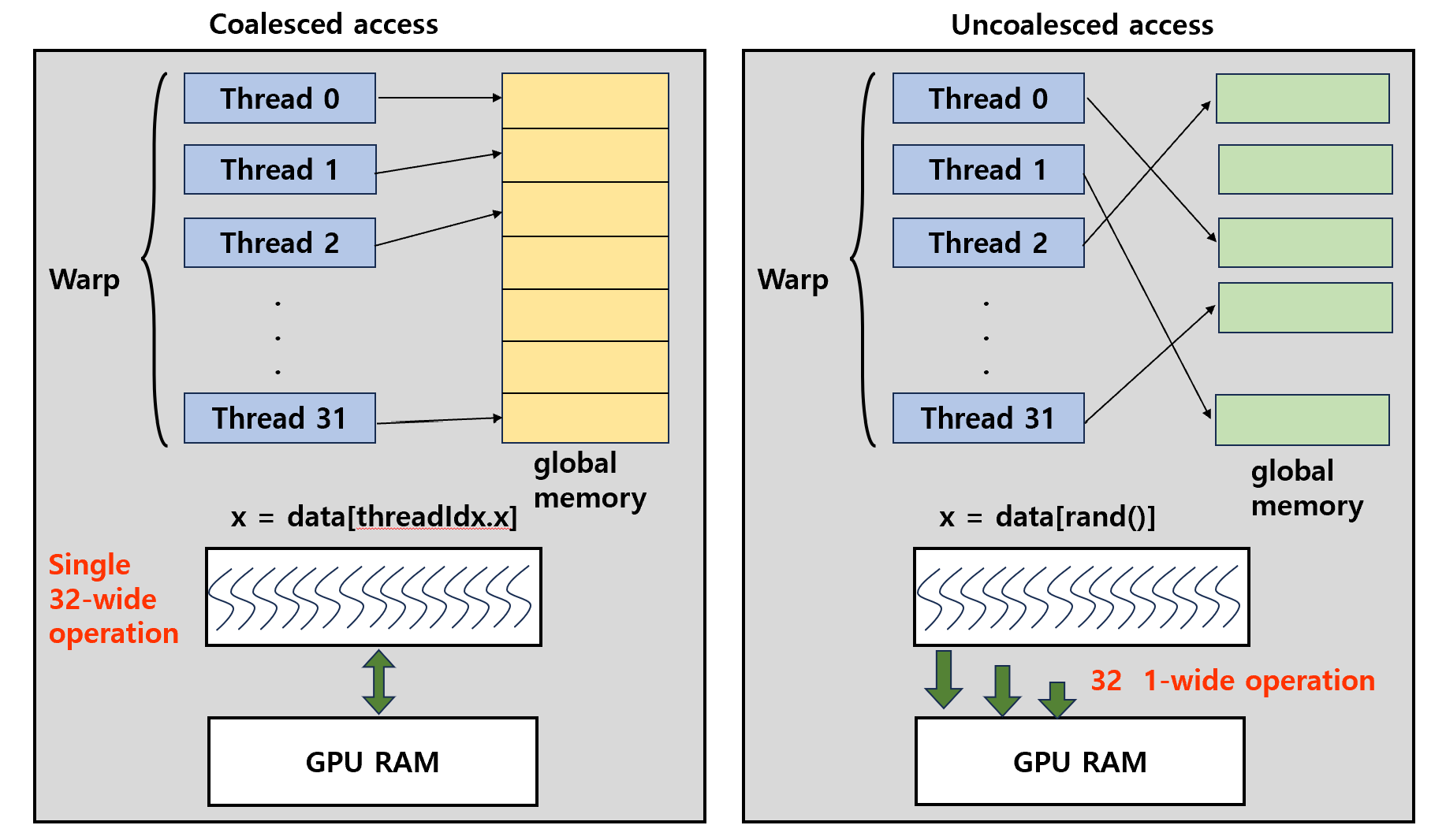
1. thread는 CPU에서 생성되고 GPU에서 실행된다 (cudaMalloc, cudaMemcpy)
2. GPU에서 thread는 block 단위로 할당되고 실행되는데, 여러 개의 thread block은 GPU내에서 warp단위로 나뉘고 SM에 스케줄링되어 SIMT방식으로 처리된다.
3. SM은 할당된 warp를 실행하는데, 각 thread는 global memory에 access하여 data를 read/write한다. -> 이 때 global memory에 access 되는 패턴이 coalesce한지 uncoalesce한지 비교하는 것이다.
- coalesced access : warp내 32개의 thread들이 인접한 data에 액세스 하여 1번의 32-wide 연산이 호출되고 1번의 cache miss를 일으킨다. bandwidth utilization은 100%이며 global memory에서 가져온 모든 data를 cache로 이동시켜 bandwidth의 낭비가 없다.
- uncoalesced access : warp 내 thread 액세스가 random하며 32번의 1-wide 연산이 호출되어 32번의 cache miss가 발생한다. 32번의 1-wide fetch가 실행되어 32*128 byte가 bus를 통해 이동한다. bus utilization은 1%미만이다.
global memory를 개선하기 위해서는 여러 가지 방법이 있는데, 그 중 하나가 coalescing을 개선하는 것이다.
coalescing을 개선하려면 data layout을 개선하여 locality를 향상시키는 방법이 있다.
- AOS data structure
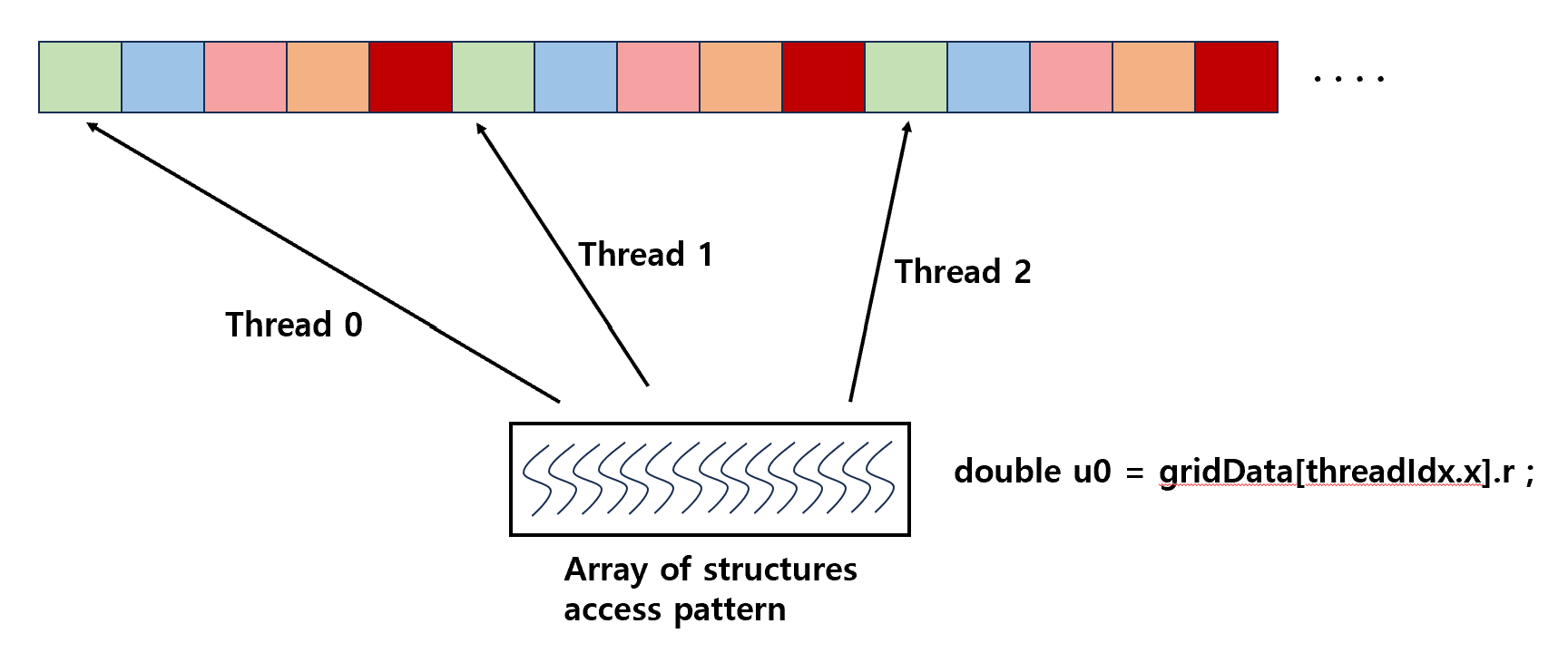
Array Of Structures access pattern : kernel 내 다른 thread에 의해 access 되는 방식이다. -> uncoalesced global memory access pattern -> cache 효율성을 위해 CPU에서 선호하는 방식
- SOA data structure
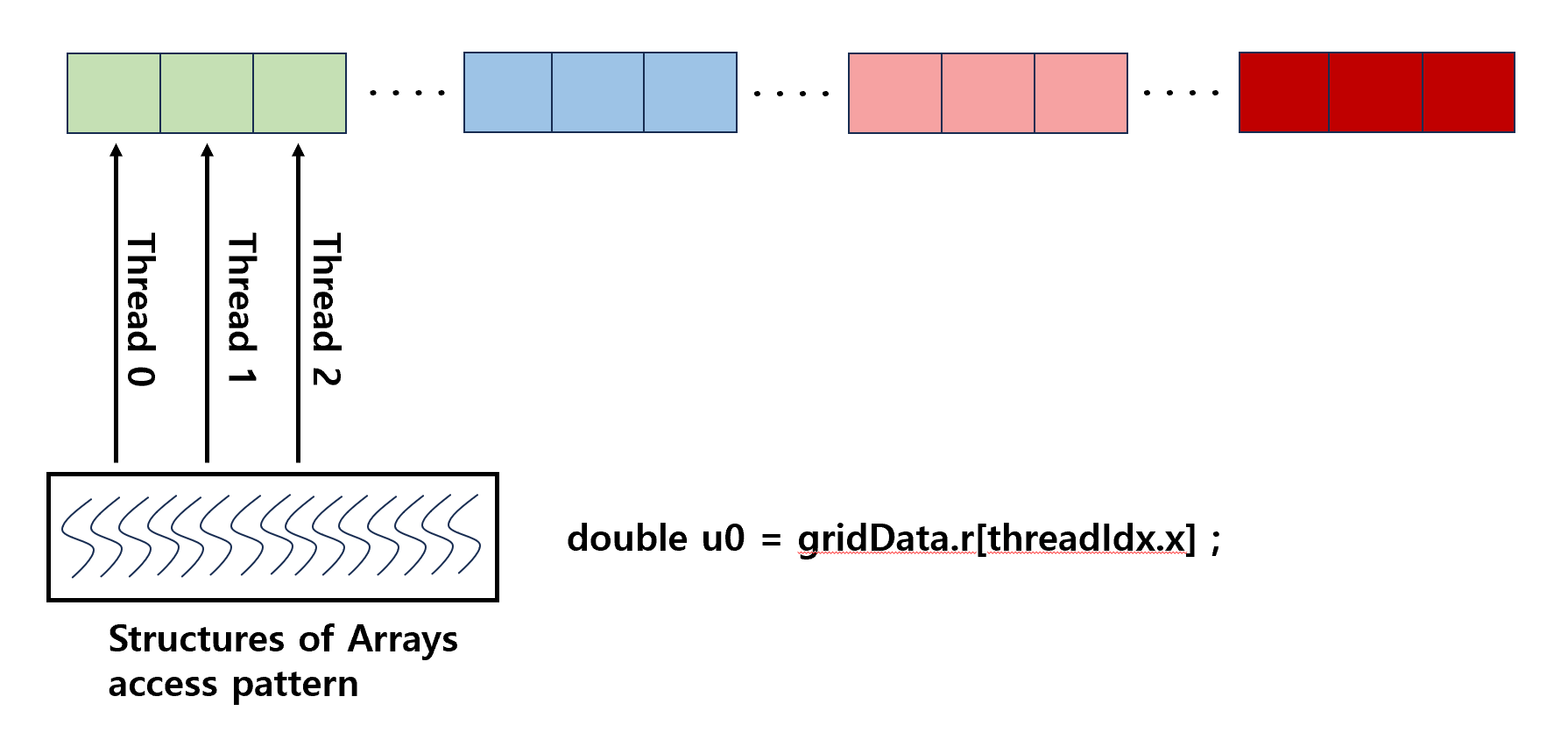
Structures Of Array access pattern : kernel 내 같은 thread에 의해 access 되는 방식이다. coalesced global memory access pattern -> execution 및 memory 효율성을 위해 GPU에서 선호하는 방식
따라서 AOS에서 SOA로 data structure를 변경하면 bottleneck이 해결된다.
추후 gpu application의 performance를 측정할 때 memory throughput을 이해하는 것은 중요하다.
<memory throughput>
- application point of view : application이 request한 byte 수 계산
- hardware point of view : hardware에 의해 이동된 byte 수 계산
memory 관점에서 application을 분석하는 데 사용해야 하는 두 가지 측면
1. address pattern : profiler를 통한 global memory utilization 및 각 access 당 L1/L2 transaction
2. # concurrent accesses in flight : GPU는 latency hiding architecture이므로 bandwidth를 saturate시키는 것이 중요하다.
'CUDA Programming' 카테고리의 다른 글
| [CUDA] ch3. CUDA Thread Programming (0) | 2024.01.16 |
|---|---|
| [CUDA] ch2. CUDA Memory Management - Shared memory & Texture memory & Registers (0) | 2023.12.18 |
| [CUDA] ch1. Introduction to CUDA Programming (0) | 2023.12.11 |

