
Kim Seon Deok
[Quantitative approach] ch2.3 Ten Advanced Optimizations of Cache Performance ~ 2.4 Virtual Memory and Virtual Machines 본문
[Quantitative approach] ch2.3 Ten Advanced Optimizations of Cache Performance ~ 2.4 Virtual Memory and Virtual Machines
seondeok 2023. 12. 8. 10:45
2.3 Ten Advanced Optimizations of Cache Performance
[cache optimization metric]
- hit time
- miss rate
- miss penalty
- cache bandwidth
- cache power comsumption
[개선된 cache optimization 방법]
Small and Simple First-Level Caches to Reduce Hit Time and Power
cache hit의 critical timing path
- tag memory에 주소 접근
- tag value와 address 비교 : address의 일부를 index로 사용하여 해당 블록의 tag와 비교
- multiplexer 설정 : cache가 set associative 방식을 사용하고 있다면 올바른 data를 담고 있는 item을 고르기 위해 multiplexer를 설정해주어야 한다.cache의 associativity가 낮다면 적은 cache line에 액세스하게 되어 power를 줄일 수 있다.(direct mapped cache라면 data의 transmission과정과 tag check을 overlap시킬 수 있다.)
microprocessor 세대로 접어들면서 L1 cache의 size가 증가함으로 인해 clock rate영향이 증가하면서 on-chip cache의 양은 대폭 증가했다. 그에 따라 cache design은 더 큰 cache로 바뀌어 가기 보다는 associativity를 늘리는 방식으로 바뀌어 갔다. 또한 associativity를 늘릴 때 address aliase(서로 다른 주소가 동일한 cache block에 매핑되어, 이 두 주소에 대한 접근이 영향을 미치는 것) 제거에 대한 가능성도 함께 고려해 주어야 한다. fully associative cache의 경우 어떤 address든 어떤 위치에 저장될 수 있으므로 aliase 문제가 없지만 구현이 복잡하고 비용이 많이 든다. 따라서 적절한 aliase를 고려해야 한다.


cache access에서 사용되는 energy를 결정하는 것은 cache 내부 block 갯수이다.
block 갯수는 액세스 되는 row의 갯수에 비례한다. block size가 증가하면 row의 갯수가 줄어들고 miss rate가 증가한다.
따라서 이에 대한 대안으로 cache를 bank로 organize하여 내가 찾고자 하는 블록이 위치하는 bank에만 액세스하도록 만들어서 energy 사용을 줄이도록 할 수 있다.
Second Optimization: Way Prediction to Reduce Hit Time
way prediction
cache에서 따로 남겨진 bit인 block predictor bit은 next cache access를 predict하기 위해 남겨진다.
prediction은 찾고자 하는 block을 미리 선택하는 것이다.
single tag comparison이 cache data를 읽으면서 parallel하게 수행되고 miss가 발생하면 next clock cycle에 hit될 다른 block들을 찾는 것이다.
- predictor가 correct하다면 cache access latency = hit time
- predictor가 incorrect하다면 cache access latency = latency of extra clock cycle
way selection
way prediction의 확장된 형태로, power consumption을 줄이기 위해 사용될 수 있다.
way predictoin bit을 사용해서 어떤 cache block이 실제로 액세스되는 지를 결정하는데, way prediction이 correct하다면 power를 save하지만, misprediction이 일어나는 경우 tag match와 selection작업이 반복되어 상당한 시간이 추가된다.
Third Optimization: Pipelined Access and Multibanked Caches to Increase Bandwidth
cache access를 pipeline화 하거나 multiple bank를 사용해서 cache bandwidth를 증가시킬 수 있다.
이 방식은 주로 access bandwidth가 instruction throughput을 제한하는 L1 cache에 주로 적용된다.
L1 cache pipeline는 clock cycle을 더 높이지만, latency cost를 높이기도 한다.
sequential interleaving
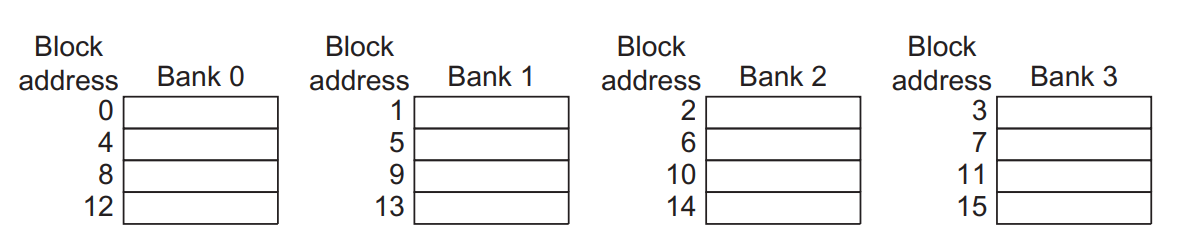
block의 address를 bank간 sequential하게 분산시키는 방식이다
→ address / 4의 나머지에 따라 bank에 골고루 분산시키는 방식
multiple bank는 또한 cache와 DRAM에서 power consumption을 줄인다.
Fourth Optimization: Nonblocking Caches to Increase Cache Bandwidth
nonblocking cache, lock-free cache
data cache가 cache miss가 발생한 동안 계속해서 다른 cache hit을 받을 수 있게 하는 것
즉 “hit under miss”최적화 방식으로, miss가 일어난 동안 프로세스의 request를 계속 받아서 miss penalty를 줄여나가는 방식이다. high-end 프로세서에서는 “hit under multiple miss”=“miss under miss”방식으로 multiple miss가 발생했을 때 다른 cache hit을 받아서 miss penalty를 줄이기도 한다. 사실 cache miss를 통해 반드시 stall이 발생하는 것은 아니기 때문에 nonblocking cache의 성능을 측정하기는 어렵다. 그러므로 effective miss penalty(overlap되지 않은 miss penaltytime)를 구하려면 miss의 sum 보다는 프로세서가 stall되어 overlap되지 않은 time을 구해야 한다.
Nonblocking cache구현에서 발생하는 문제점
- blocking cache에서 cache miss는 프로세스가 stall하게 만들고 miss가 모두 처리되기 전까지 다른 cache access를 하지 않는다. nonblocking cache에서는 cache hit이 다음 level에서 반환되는 miss와 충돌할 수 있다. 그리고 처리되지 않은 miss들 사이에서도 충돌이 일어날 수 있다. 이런 경우 hit 보다는 miss에 priority를 높게 부여하고 충돌하는 miss를 순서대로 ordering함으로써 해결해야 한다.
- blocking cache에서는 어떤 miss가 반환되는 지 명확하게 알 수 있다. nonblocking cache에서는 이게 쉽지 않다. L1 cache에서 발생한 miss는 L2 cache로 내려가 hit 혹은 miss를 발생시킬 수 있다. 이때 L2 cache 또한 nonblocking cache라면 L2에서 L1으로 miss가 반환되는 순서는 처음 miss가 발생했던 순서와 일치하지 않을 것이다. 또한 core 가 여러 개인 multiple processor system에서는 cache access time이 일관되지 않게 되어 복잡해진다.miss가 반환될 때 프로세서는 miss를 일으킨 instruction이 load 인지 store인지, 반환된 data를 cache의 어떤 block에 놓아야 할 지도 알아야 한다. 이런 정보들은 MSHR에 저장된다.
- nonblocking cache는 여분의 logic이 추가적으로 필요하게 되어 energy 측면에서 cost가 더 많이 발생하게 된다.
MSHR(Miss Status Handling Registers)
-
- 각 MSHR은 miss가 cache에 어디로 가야 하는 지에 대한 정보와 해당 miss의 tag bit 값, miss를 일으킨 load 혹은 store instruction에 대한 정보를 가지고 있다.
- miss가 발생하면 해당 miss를 처리하기 위한 MSHR을 할당하고, miss에 대한 적절한 정보를 입력하며, memory request에 MSHR의 index를 tag로 붙인다.
- memory system은 data를 반환할 때 해당 tag를 사용하여 cache system이 data 및 tag information을 적절한 cache block으로 전송하도록 허용하며, miss 를 생성한 load 혹은 store instruction에게 이제 data를 사용할 수 있고 작업을 이어나갈 수 있다고 “notify”한다.
Fifth Optimization: Critical Word First and Early Restart to Reduce Miss Penalty
Critical word first
memory로부터 miss된 word를 요청하고 해당 word가 도착하면 프로세서로 전송
block의 나머지 word가 채워지는 동안 프로세서가 실행을 계속 이어나가도록 하는 방법
Early restart
word를 순서대로 가져오되, 요청된 block의 word가 도착하자마자 이를 프로세서로 보내서 프로세서가 실행을 계속 이어나갈 수 있게 하는 것
Sixth Optimization: Merging Write Buffer to Reduce Miss Penalty
write-through 및 write-back 방식은 모두 write buffer에 의존한다.
write buffer가 empty 상태가 되면 data와 address는 buffer에 채워진다. buffer의 block이 변경된다면 valid한 buffer block과 새로운 data가 match되는 지 확인할 필요가 있다. buffer가 꽉 찬 상태에서 address가 match되지 않는다면 프로세서와 cache는 buffer의 entry가 empty될 때까지 기다려야 한다.
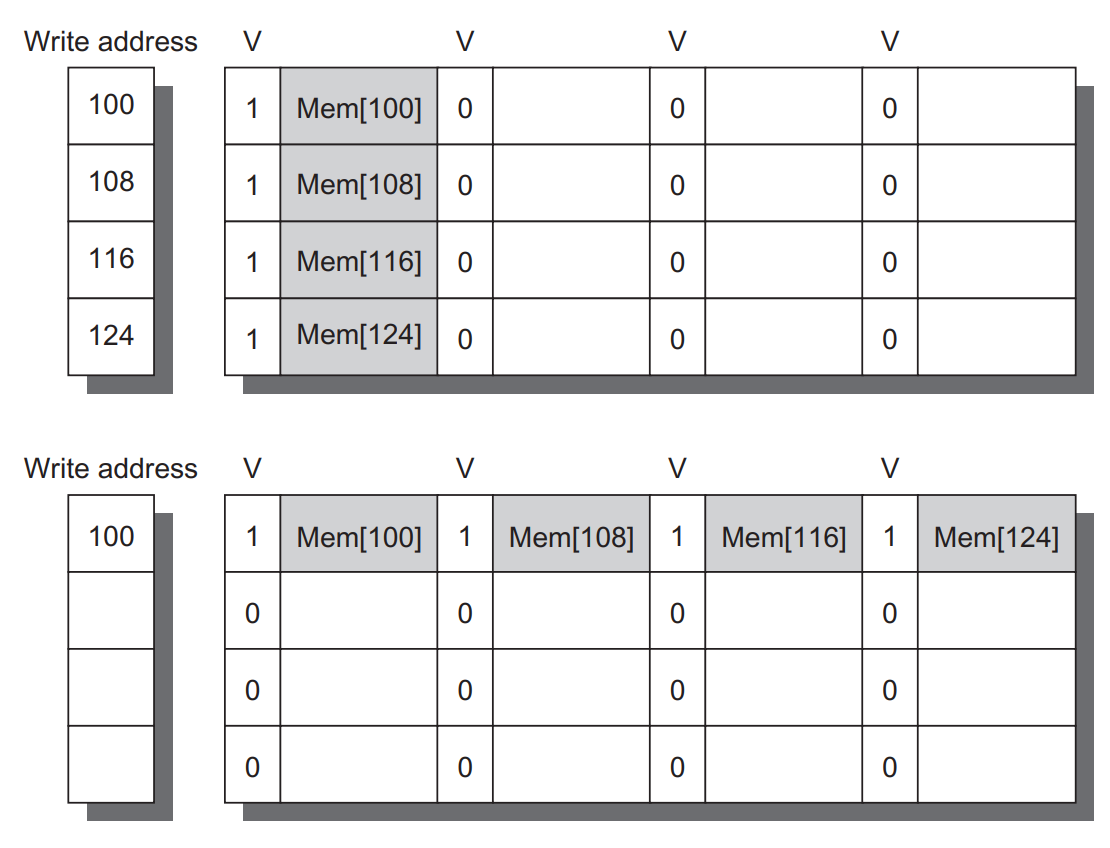
위 write buffer는 4개의 entry로 구성된다. 왼쪽은 entry address이며, 순차적으로 8바이트가 사용중인지를 나타내는 valid bit이 있다. 각 entry는 4개의 64비트 word를 갖는다.
4개의 write는 write merge를 통해 single buffer entry로 merge된다.
write buffer merge방식을 사용하지 않으면 1개의 entry 당 1개의 word씩 buffer를 채우게 된다. 하지만 write buffer merge를 하게 되면 1개의 entry에만 모든 word가 맞게 들어가게 된다.
write merge를 하게 되면 write buffer가 가득 차서 발생하는 stall을 줄인다.
Seventh Optimization: Compiler Optimizations to Reduce Miss Rate
하드웨어적인 변화 없이 소프트웨어적인 방식으로 miss rate를 줄이는 방법이다.
Loop interchange → spatial locality를 사용해서 miss를 줄이는 방식
일부 프로그램은 nonsequential한 순서대로 data에 액세스한다.
loop의 중첩된 순서를 바꾸는 loop interchange기법은 프로그램이 store된 순서대로 data에 액세스하도록 한다.
이를 통해 spatial locality를 증가시킬 수 있다.
ex) 2차원 배열 [5000,100]의 경우, x[i, j]와 x[i, j+1]의 경우 row major 방식(row순서대로 data가 채워짐)으로 adjacent하다. (1 block = 1 row)
/* Before Loop Interchange */
for (j = 0; j < 100; j ¼ j + 1){
for (i = 0; i < 5000; i ¼ i + 1)
x[i][j] ¼ 2 * x[i][j];
}위 코드의 경우 row를 나타내는 변수 i에 대해 stride가 100씩 증가한다. (즉 1block에 접근하는 데 stride가 100)
즉 1 cache block의 1 word에 접근하고 다음 cache block으로 넘어간다.
/* After Loop Interchange */
for (i ¼ 0; i < 5000; i ¼ i + 1){
for (j ¼ 0; j < 100; j ¼ j + 1)
x[i][j] ¼ 2 * x[i][j];
}위 수정된 코드의 경우 row를 나타내는 변수 i에 대해 stride가 1씩 증가한다.
그렇기 때문에 다음 block으로 이동하기 전에 1 cache block의 모든 word에 접근하게 되고 cache performance는 향상된다. -> instruction execute횟수에 영향을 주지 않고 cache performance를 증가시키는 최적화 방법이다.
Blocking → temporal locality와 spatial locality의 조합을 사용해서 miss를 줄이는 방식
matrix를 row major 방식 혹은 column major 방식으로 store하는 것은 사실 모든 loop iteration을 통 row와 column에 접근하기 때문에 실질적으로 문제를 해결하지 않는다.
data가 replace되기 전에 cache로 load 된 data에 대한 액세스를 극대화 하기 위해 matrix의 전체 row나 column에 액세스 하지 않고 submatrix나 block에 대한 연산을 수행하는 blocked algorithm을 사용한다.
/* Before Blocking */
for (i = 0; i < N; i = i + 1)
for (j = 0; j < N; j = j + 1){
r = 0;
for (k = 0; k < N; k = k + 1)
r = r + y[i][k]*z[k][j];
x[i][j] = r;
};위의 코드는 z matrix의 모든 NXN element를 읽고, y matrix의 한 row에 있는 N번째 element를 반복적으로 읽어서 x matrix의 한 row에 있는 N번째 element에 write하는 작업이다. (y matrix의 i번째 row 와 z matrix의 j번째 column을 곱함)
위 방식은 모든 row와 column에 액세스한다.

기존에는 이런 방식으로 matrix multiplication이 일어난다. → 1개의 element를 계산하기 위해 1row와 1column의 모든 element를 모두 액세스 해주어야 한다.
- x[i][j]는 맨 처음에 한번도 액세스되지 않았기 때문에 N^2의 compulsory miss가 발생하게 된다.

- matrix y의 i번째 row의 element는 matrix z의 j번째 column의 element와 곱셈연산을 한다.matrix y의 row 길이가 cache길이보다 길다면, i번째 row의 element는 replace되기 전에 reuse되어야 한다. → n^3 capacity miss 발생
- i는 고정되고 j는 증가하니까 matrix y의 row는 N^2번 반복되어 연산
- matrix z의 길이가 cache의 길이보다 길다면, matrix z에 해당하는 모든 액세스에는 miss가 발생 → n^3
- 따라서 total compulsory/capacity miss 횟수 = 2n^3 + n^2
/* After Blocking */
for (jj = 0; jj < N; jj = jj + B)
for (kk = 0; kk < N; kk = kk + B)
for (i = 0; i < N; i = i + 1)
for (j = jj; j < min(jj + B,N); j = j + 1){
r = 0;
for (k = kk; k < min(kk + B,N); k = k + 1)
r = r + y[i][k]*z[k][j];
x[i][j] = x[i][j] + r;
};element가 cache에 맞도록 하기 위해 앞서 이전의 코드에서 BxB크기의 정사각형 submatrix에서 계산하도록 수정한다.
내부 loop는 x와 z의 길이가 아닌 크기 stride B로 계산된다.
이 때 B는 blocking factor이다.

- NxN/B submatrix는 첫번째 element가 reuse되기 전에 액세스.
- 만약 row > cache라면 submatrix에서 액세스 하는 동안 miss 발생
- N/B x N/B x N x B 는 x에 액세스 → N^3 / B miss
- j 루프는 반복적으로 y의 i번째 행에서 submatrix B의 row에 액세스
- B는 j 루프의 첫 번째 반복에서 miss가 일어나고 그 이후로는 hit 발생
- N^3/B^2/B = N^3/B miss
- i 루프는 반복적으로 z의 BxB 요소로 구성된 부분 행렬(submatrix)에 액세스.
- i 루프의 첫 번째 반복에서는 B^2 miss가 일어나고 그 이후로는 hit 발생
- N^2/B^2xB^2 = N^2miss
- 따라서 total compulsory/capacity miss 횟수 = 2n^3/B + n^2

blocking cache는 execution을 overlap함으로써 miss penalty를 줄인다.
따라서 cache 기반 프로세서에서 matrix를 주요 data structure로 사용하는 애플리케이션의 경우, 좋은 performance를 얻으려면 cache blocking이 절대적으로 사용되어야 한다.
Eighth Optimization: Hardware Prefetching of Instructions and Data to Reduce Miss Penalty or Miss Rate
hardware prefetch
프로세서가 request하기 전에 data를 prefetch하는 것이다.
(=memory나 느린 저장장치에서 더 빠른 저장장치인 cache로 data를 미리 가져와서 프로세서가 빠르사용할 수 있게 함. cache는 프로세서가 빠르게 액세스할 수 있는 임시 memory 공간이 된다.)
instruction cache와 data cache는 main memory에 더 빠르게 액세스하는 cache나 내부 buffer로 prefetch될 수 있다.
instruction prefetch
cache 외부의 하드웨어에서 일어난다.
일반적으로 프로세서는 miss가 발생하면 request된 block과 다음 연속된 block 즉 2개의 block을 가져온다.
request된 block은 instruction cache로 올라가고, prefetch된 연속된 block은 instruction stream buffer로 올라간다.
만약 request된 block이 instruction stream buffer에 있는 경우, cache request는 취소되고 block은 instruction stream buffer에서 read되며 다음 prefetch request가 발생한다.
hardware data prefetching은 ususe되는 memory bandwidth를 활용하는 것에 따라 달라진다.
demand miss와 충돌하게 되면 data prefeching의 성능은 오히려 감소될 수 있다.
hardware data prefetching으로 load된 data가 사용되지 않거나, prefteching으로 인해 빈번하게 사용되던 data가 replace되면 오히려 power consumption을 증가시키게 된다.
Ninth Optimization: Compiler-Controlled Prefetching to Reduce Miss Penalty or Miss Rate
프로세서가 필요로 하기 전에, 컴파일러가 data를 request하는 prefetch instruction을 사용하는 방식이 있다.
- Register prefetch : 값을 register에 미리 load
- Cache prefetch : 값을 register가 아니라 cache에 미리 load
nonfaulting cache prefecth, nonbinding prefetch
data를 미리 load하여 cache에 올려두는 거지만, 이로 인해 register나 cache의 내용을 변경하는 exception이나 error가 발생하지 않게 하는 것이다. 즉 프로그램의 동작에 영향을 미치지 않는 prefetch된 data가 cache에서 프로세서로 반환될 때까지 기다리는 동안 data cache는 stall하지 않고 계속해서 instruction과 data를 제공해야 한다.
hardware prefetch에서처럼 data를 미리 load해오는 동안 execution을 overlap해야 한다.
loop는 prefetch에 적합한데, miss penalty가 작다면 컴파일러는 루프를 1번 내지는 2번 unroll(기존 루프가 한 번 반복할 때 반복을 더 많이 하게 만들어, 전체적인 루프 반복 횟수를 줄이는 것)하고 prefetch를 execution과 함께 scheduling한다.
만약 miss penalty가 크다면 software pipelining을 사용하거나 나중의 iteration을 위해 많이 unroll한다.
Tenth Optimization: Using HBM to Extend the Memory Hierarchy
[block size가 커지면 발생하는 문제점]
- fragmentation problem : 많은 block의 내용이 필요하지 않은데 block을 전송하게 되면 cache가 비효율적으로 사용될 수 있다. → solution) subblocking : block의 일부를 invalid하게 만드는 subblocking 방식을 사용
- DRAM cache에 있는 block의 갯수가 줄어들어 conflict 및 consistency miss가 발생할 수 있다.
[block size가 작아지면 발생하는 문제점]
block size가 작아지면 tag storage를 설정하는 것에 문제가 생기게 된다.
→ solution 1) L4 cache의 tag를 HBM에 저장
이 방식을 사용하면 맨 처음에 tag에 접근 그러고 나서 data에 접근을 해야 하므로 액세스를 2번 해야 한다. 이 때 L4 cache까지 액세스하는 데 걸리는 access time은 100cycle 이상이므로 이 방식은 매우 비효율적이다.
→ solution 2) tag와 data를 HBM SDRAM의 동일한 row에 저장
tag에 먼저 액세스하고 tag가 hit이면 data에 액세스하기 위해 column액세스를 사용
row를 open하는 데에는 많은 cycle이 소요되지만 동일한 row내부 다른 부분에 액세스하는 데 필요한 CAS latency는 새로운 row access time의 1/3이다.
cache optimization 방법 요약

2.4 Virtual Memory and Virtual Machines
virtual memory는 physical memory를 secondary storage(disk나 SSD)의 cache역할을 하게 만드는 것이다.
Protection via Virtual Memory
운영체제와 아키텍쳐는 프로세스가 하드웨어 자원을 공유하지만 서로 영향을 줄 수 없게끔 프로세스 관리와 시스템 안정성을 유지하는 데 중요한 역할을 한다.
- 프로세스는 사용자 프로세스가 실행되는 user mode, 운영체제 프로세스가 실행되는 kernel mode에서 실행된다.
- 유저가 프로세스를 read할 수는 있지만 write할 수는 없는 프로세스 상태를 제공해야 한다.
- system call을 사용해 user mode에서 kernel mode로 전환되도록 해야 한다.
- 프로세서는 다른 process로부터 특정 process의 memory 상태를 보호하기 위해 memory access를 제한해야 한다.
rotection via Virtual Machines
virtual machine
넓은 의미 : 표준 소프트웨어 인터페이스를 제공하는 모든 emulation 방법
VM은 하드웨어와 동일한 ISA를 지원하지만 새로운 ISA로 migrate할 경우에는 새로운 ISA로 migrate가 완료될 때까지 기존 ISA 소프트웨어를 사용할 수 있게 지원한다. 이 때 VM을 operating system virtual machine이라 한다.
virtual memory와 관련된 idea중 하나인 virtual machine은다음과 같은 목적으로 사용되고 있다.
- modern system에서 isolation과 security의 중요성 증가
- 표준 OS의 security 및 reliability문제 → 각 application을 별도의 컴퓨터에서 compatible한 OS version을 사용해 실행하도록 하면 server의 reliability를 높일 수 있다.
- 관련 없는 user 간 single computer(data center, cloud)를 공유
- 프로세서의 raw speed가 증가하면서 VM의 overhead가 수용 가능해짐
single computer는 multiple VM을 실행시키며 여러 다른 OS를 지원한다. 즉 VM에서는 여러 OS가 하드웨어 resource를 공유한다.
virtual machine monitor(VMM), hypervisor
VM을 지원하는 소프트웨어이자 VM의 핵심이다.
virtual resource를 physical resource에 어떻게 매핑할 지 결정한다.
VMM의 목적은 가능한 많은 instruction을 native hardware에서 direct하게 실행하는 것이다.
user level processor-bound 프로그램은 OS가 거의 호출되지 않으므로 virtualization overhead가 없고 모든 작업이 native 속도로 진행된다.
I/O-intensive workload는 OS-intensive이며 I/O 요청을 빈번하게 하므로 system call을 주로 사용하고 privilieged instruction으로 인해 virtualization overhead가 높다.
컴퓨터에 연결된 I/O 장치 수가 많고 I/O 장치 유형이 다양해지면서 I/O는 system virtualization을 하기에 가장 어려운 부분 중 하나이다. VMM은 VM의 일관성을 유지하기 위해 각 VM에 각 유형의 I/O장치 드라이버의 일반 버전을 제공한 다음 실제 I/O를 처리하도록 해야 한다.
VM의 benefit
- Managing software : VM은 과거 OS를 포함해 완전한 소프트웨어 stack을 실행할 수 있는 abstraction을 제공하여 과거 OS와 최근 새롭게 배포된 OS를 모두 실행할 수 있다.
- Managing hardware : 여러 서버에서 다양한 application을 각각 다른 OS version으로 실행하도록 하면 별도의 소프트웨어 stack이 독립적으로 실행되면서 하드웨어를 공유할 수 있게 되고 서버 갯수를 통합할 수 있다.→ cloud computing의 발전으로 전체 VM을 다른 phisycal processor로 swap out하는 것이 가능해졌다.
- 최신 VMM은 실행 중인 VM을 다른 컴퓨터에서 실행하도록 하는 migration기능을 제공한다. 따라서 load balancing 혹은 하드웨어가 고장난 경우 해당 VM으로 옮겨와서 실행을 이어나가는 것이 가능해졌다.
Requirements of a Virtual Machine Monitor
VMM은 guest system이 virtual 리소스와만 상호작용하도록 보장해야 하므로 guest OS는 VMM 위에서 user mode로 실행된다.
guest OS가 privileged instruction을 사용해 하드웨어 리소스와 관련된 정보에 액세스 하거나 수정하려 하면(guest page table pointer를 사용해 read or write) VMM으로 trap된다. 그 다음 VMM은 실wp 리소스에 대한 적절한 변경을 수행할 수 있다.
VMM의 기능
- guest software에게 software interface를 제공
- guest의 status를 서로 격리시킴으로써 guest os를 포함한 guest software로부터 스스로를 protect
- VMM은 guest software가 native hardware에서 실행되는 것처럼, VM에서도 정확히 똑같이 동작해야 한다.
- guest software는 VMM이 guest 간 충돌을 막고 리소스를 안정적으로 관리할 수 있게 실제 시스템 리소스 할당을 변경하면 안된다.
- 프로세스를 virtualizae하려면 VMM은 guest VM보다 더 높은 수준의 권한을 가져야만 한다 → privileged instruction은 VMM에 의해 컨트롤되어야 하며, guest VM은 user mode에서 실행된다.
- timer interrupt의 경우, VMM은 현재 실행 중인 guest VM을 중단하고 VM의 상태를 저장 → interrupt 처리하고 다음에 실행할 guest VM을 설정 → 저장했던 상태를 다시 load
- timer interrupt를 필요로 하는 guest VM은 VMM에 의해 virtual timer를 제공받는다.
- VMM은 system mode와 user mode에서 동작한다.
- system mode에서만 실행 가능한 privileged instruction이 필요하며, 해당 instruction은 유저 프로세스가 시스템 리소스에 접근을 하지 못하도록 제어 한다.
VM의 각 guest OS는 자체 page table을 관리한다는 점으로 인해 virtualization이 어려워지게 된다.
이를 해결하기 위해 VMM은 real memory와 physcial memory를 분리하고, real memory를 virtual memory와 physical memory의 중간 level로 만든다.
⇒ virtual memory - physical memory - machine memory
guest OS는 page table을 사용해 virtual memory를 real memory로 매핑하고, VMM page table을 사용해 real memory를 physical memory로 매핑한다. 여기서 VMM page table은 shadow page table이다.
guest의 page table에 대한 모든 수정 사항을 detect해서, shadow page table entry guest OS 환경의 entry와 일치하도록 만든다. VMM은 guest OS가 guest page table을 변경하거나 page table pointer에 액세스하려는 모든 시도를 priviliged instruction을 사용해 감지해야 한다.